
#3 - How We Drive Developer Productivity at Yelp | with Kent Wills, Director of Engineering, Engineering Effectiveness at Yelp
You won't say no to a yelping hand.


Hello friends, for this third in-depth article, we are welcoming Kent Wills, Director of Engineering at Yelp who will unveil the fascinating story of Yelp's decade-long (and ongoing) quest for Engineering Effectiveness. But first, a bit more about him👇

Kent Wills, Director of Engineering, Engineering Effectiveness at Yelp
It’s not a famous director who just received an Oscar. But it’s still a director… of Engineering. Let me introduce you to Kent Wills, Director of Engineering, Engineering Effectiveness at Yelp.

In the picture above, he’s posing with Plato’s “Highest-Rated Mentor” Award, which he deserved through his dedication to mentees, sharing his insights year after year. 🏆
We couldn’t be prouder to have him around for so long! And we guess that Yelp is as proud as we are: he will soon celebrate 10 years in the company. 10 years during which he saw the company grow from 200 to 1300+ engineers, and where his own Engineering Effectiveness team expanded from 6 to 70 engineers. Each company stage he went through felt like a whole different adventure.
…but what’s Engineering Effectiveness? We won’t spoil it, and Kent will explain that better right below anyway. He used his talk at Elevate 2023 as a starting point to write an in-depth, actionable guide about how he and his team drive developer productivity at Yelp.
If you’d rather see the video, just check below - but we strongly advise you to also read the article!
Without further ado, I’ll let Kent take over and start sharing the 10-year journey of Engineering Effectiveness at Yelp. Let’s go!
For more from Kent, follow him on LinkedIn or check out his Plato Mentor Profile.
How we drive Developer Productivity at Yelp
It’s rare to experience a company through multiple stages of growth and maturity. Over the past decade, I have been fortunate enough to be part of that journey at Yelp as an Individual Contributor, Manager, and Director. All of this while supporting an amazing mission with amazing people, at scale (33M App unique devices).
You could say I have grown up in the developer productivity world before the industry had a name for it. Our name was Engineering Effectiveness (“EE”) where I started managing Webcore in 2016 and over the past 4 years, I have grown the Engineering Effectiveness group to 70+ engineers, 2 groups, and 9 teams supporting 1,300+ Engineers at Yelp.
It’s been a long journey and now is a fitting point to reflect on it with you as I share the problems we faced and how we solved them at each stage and scale of Yelp. My hope is that sharing how and why we made the decisions we have over the years can help you think critically about the changes you want to see in your own organizations.
So what is Engineering Effectiveness anyway?
Engineering Effectiveness aims to increase Engineering capacity through organizational efficiency. At Yelp, we have a dedicated, lean group of Engineers focused on solving broad, long-term problems to reap efficiency benefits at scale. These solutions result in core systems and workflows called “paved paths,” a concept inspired by Netflix. I’ve always loved this description because it evokes imagery of well-engineered, centralized infrastructure benefiting the masses. It allows users to effortlessly pursue their individual goals, unhindered by the system’s underlying complexity.
Supporting developers, Engineering Effectiveness is dedicated to removing obstacles that impede developers’ productivity. This expansive charter allows us to work on a wide range of projects, though it sometimes creates ambiguity regarding our group’s role with partners like Infrastructure and Security.
In contrast to DevOps, which blends software engineering practices with operations teams, our focus is primarily on the application layer. As such, I report to our Product group rather than our Infrastructure group. Lately, the popular industry term for these groups is “developer productivity,” but even so, each company tends to have its own “flavor” of these groups and teams.
Let 1,000 flowers bloom. Then rip out 999 of them.
- Peter Seibel
The term “Engineering Effectiveness” (EE) was first introduced to my predecessor through Peter Seibel’s article, “Let 1,000 flowers bloom. Then rip out 999 of them.” Peter, an engineering lead for the Engineering Effectiveness group at Twitter (now X 👎) struggled with two major challenges. First, engineers had the freedom to use whatever technology they preferred leading to a proliferation of individualized systems (“letting 1,000 flowers bloom“). Second, without centralized support—a challenging feat given the multitude of systems—the group struggled to operate efficiently at scale.
At this stage, it made sense to slim down to a few systems that were supported by a few engineers and leave the rest (“rip out 999 of them“). Peter went on to model a curve of the impact of adding engineers toward this centralized function as a way to increase overall engineering capacity without hiring more engineers.
The creation of EE, with a handful of founding members, began after we had 200 engineers in Yelp Engineering and after we had achieved product market fit. The systems we were going to build would stand the test of time. Our first problem was shipping code from our monolith as our Engineering group continued to expand.
Yelp’s EE Journey: Part 1 – The Monolith Problem
In 2013, with around 200 engineers, the Consumer and Business Owners group started hitting scaling issues. My predecessor went to the manager at the time (now the VP of Consumer) and shared how the monolith was increasingly impacting our ability to ship code into production.

Like many tech companies, Yelp has its own monolith story to tell. With hundreds of developers and a couple million lines of Python code, pushes to production transformed into a meticulously scheduled and coordinated endeavor. With our system, developers would click “Pick me” in a UI, which checked if tests ran successfully before attempting to merge with others. As time went on, these scheduled pushes went from only a few engineers to 20–30 attempting daily deployments.
With our guiding principle: “you write code, you write a test,” Yelp Engineering had figured out a way to ship with a large team working in the same code base. Yet, we reached an inflection point where the increasing probability of a rollback in a single deployment became a problem. Analyzing deployment trends, my predecessor discovered a problem: within a few months, every deployment attempt would likely have at least one rollback. The clock was ticking.
This was the first defining problem for EE and solving that problem helped shape our group over the resulting years.
How did we scale engineering with a monolith? By switching to a service-oriented architecture.
However, in the midst of figuring out how to transition, we encountered new problems at scale. As I mentioned earlier, all engineers wrote tests, and that’s a good thing. It substantially increased the reliability of deployments with hundreds of developers. However, as we scaled our engineering organization, we had so many tests that if you had run them sequentially, it would have taken two days to run. Compounding the issue, every engineer ran the entire test suite for their branches, could be picked in a push, and the dedicated push manager ran this again for the merged branches prior to shipping the code to production n.
To support the monolith EE and partner teams solved the following problems:
How do we run tests in a reasonable amount of time? → Create a distributed system for running tests that we called Seagull at first and now refer to as JOLT.
How do we optimize the build? → Database load times and first builds of the monolith became slower so we instrumented Docker (which led to other solutions like dumb-init) as a pre-built cache and Waf as a distributed build system.
How do we know who owns what? → We moved from using ‘git blame’ to embedding metadata to capture ownership at the team level for code.
How do we encourage code consistency? → Pre-commit, developed at Yelp. This was born out of EE Engineers frequently commenting on PRs about code formatting. Yes, there is a Python Style Guide, but one thing we discovered over the years is if you don’t programmatically enforce guidelines, they will be variably upheld. And who wants to bikeshed on whether we should use tabs or spaces?
Solving problems for a complex system like the monolith meant that we needed ever-increasing complex solutions. This image was our distributed system at the time, just to support running tests at scale.
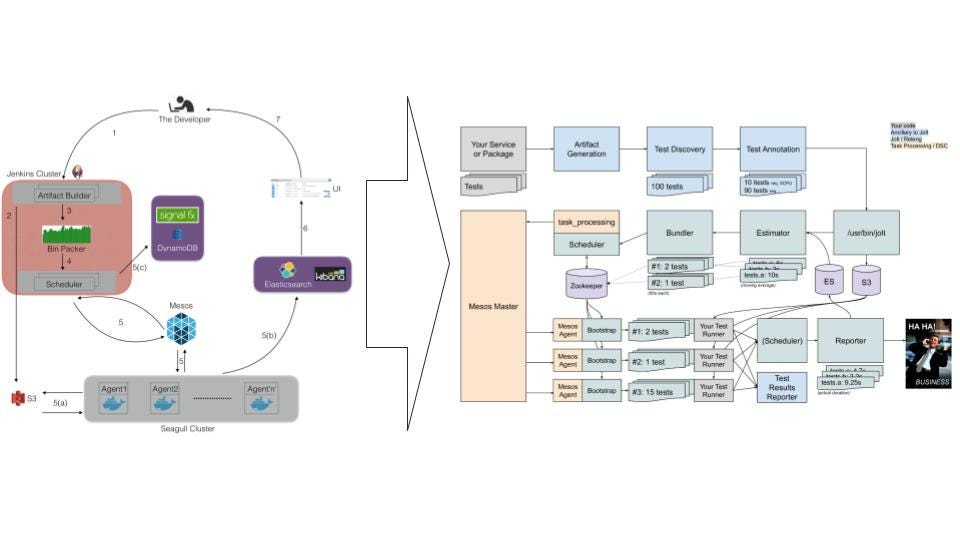
A guiding mantra over the years at Yelp was “don’t fix it until it becomes a problem.” This helped us focus on solving the most important problems but also resulted in burnout. I’m not sure we could have moved forward in any other way, as I doubt we would have had the institutional support to start working on these problems any earlier than we did.
Yelp’s EE Journey: Part 2 – SOA (Service-Oriented Architecture)
As we were solving our monolith issues, we re-focused our efforts on phase 2 in 2015, when we had around 300 engineers and 30 members of the EE team. This was our journey to the service-oriented architecture (SOA) era. The renewed focus: How do we scale services effectively?
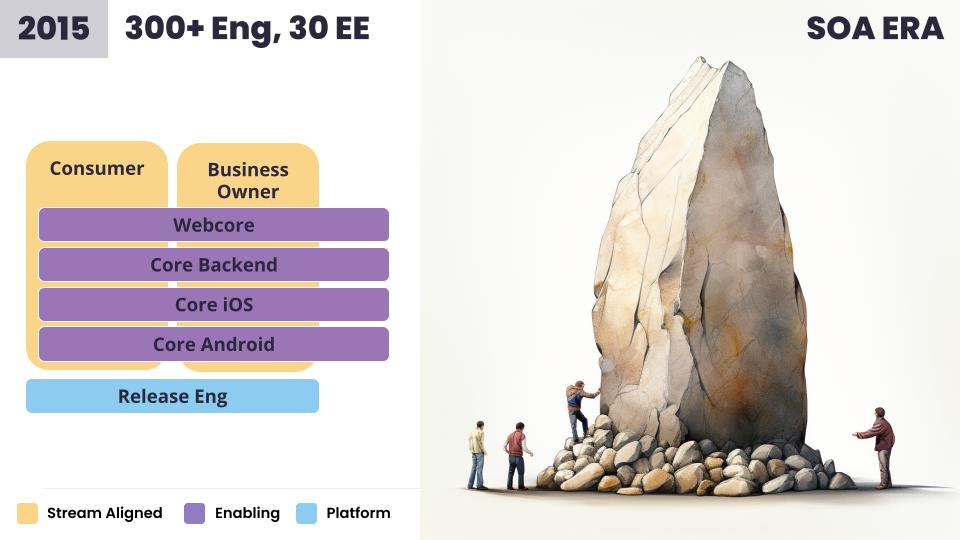
At this stage, we wanted to proactively help teams write their services in a consistent, best-practice way. I’d like to say we figured out all the problems before we went down this path, but we were figuring it out as we went.
To scale services we solved the following problems:
How do we ensure the consistency of styles and encourage accessible product flows? → Our Design System.
This helped us maintain a consistent, best-practice way of styling Yelp while also eliciting broad re-use. It’s worth noting that the term “Design System” wasn’t common then. We originally called it the Style Guide and later adopted the terminology with the rest of the industry.
How do we test across service boundaries? → Acceptance testing with a Docker Compose-like tool (Yelp Compose or YCP).
We ended up building our own orchestration framework to spin up an entire service to use for testing. This was built on top of PGCTL or Playground control which could spin up a variety of services needed to run a web app locally on a devbox to visualize changes.
How do we track/support migrations across services? → Migration Status, All Repos Fixer, Yokyo Drift.
Engineering orgs are perpetually migrating, whether to new supported technologies or simply bumping external dependencies. Initially, when we had a small enough engineering group and codebase, we managed the migrations ourselves. However, with a lean team and a growing organization, we had to change the model.
We shifted to a new approach, monitoring migrations across all these services and implementing the hardest migrations to create examples for others. We used two systems: EE metrics to display stats to teams and Yokyo Drift to manage drifting dependencies. And that’s what we have today. We monitor all the dependencies across all of the services across all of Yelp. This means that we immediately know what systems are at risk if there is a security vulnerability (think log4j) and we understand how many major/minor/patch versions away we are from making the fix.
I used to call this dependency drift “unobserved debt” because engineers didn’t realize the impact of not upgrading a package/library until they needed something. At that point, an issue that could have taken a day to resolve may have turned into a month-long project delay.
How do we encourage teams to move out of the monolith? → Service Templating, Developer Playgrounds, modern tech stack.
The adoption of service-oriented architecture (SOA) made team ownership attribution easy. Gone were the days of ambiguous code ownership! To help teams move out of the monolith, we also drew them out with modern tech stacks with common logic that could be shared with legacy systems.
How do we encourage quality? → Pre-Commit, Ownership, Testing Analytics.
Pre-commit naturally extended from the monolith to services and ownership built the foundation of our metrics dashboards for teams today.
Below is an example of our Ownership service:
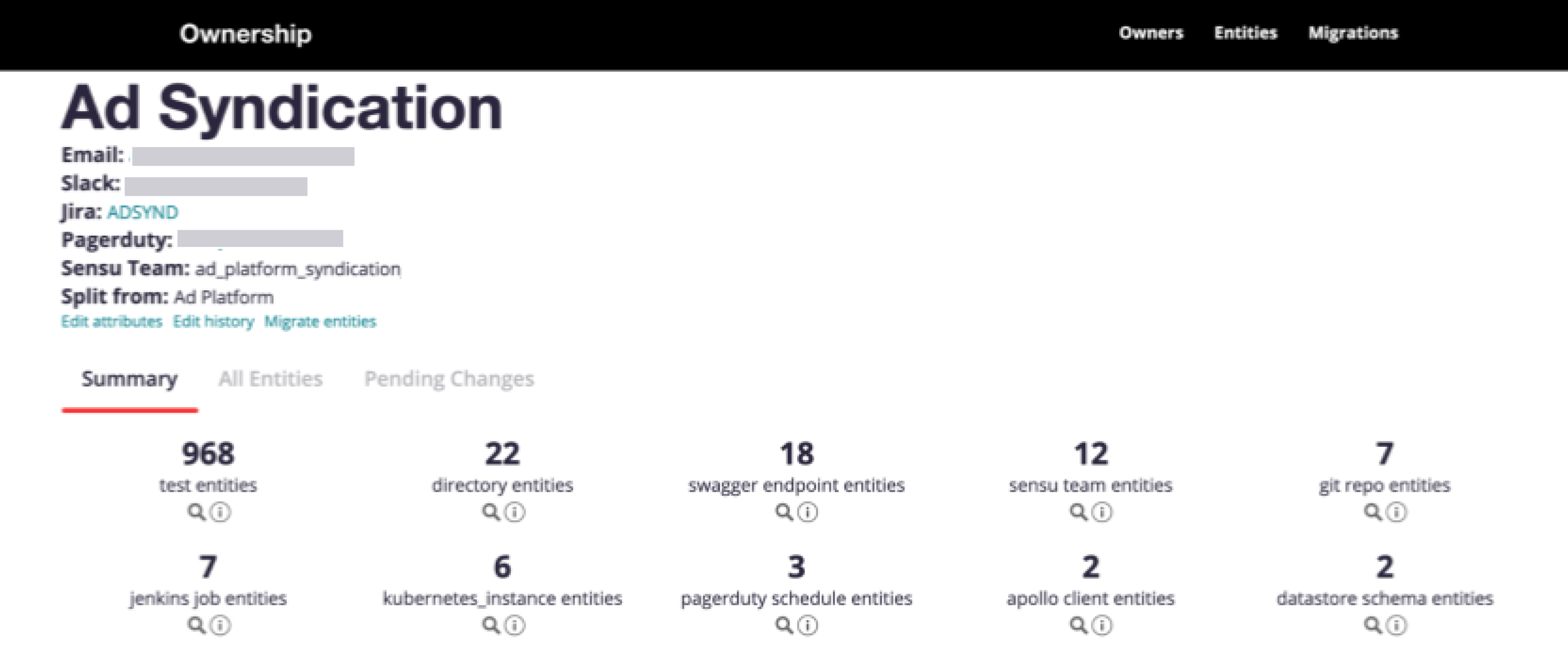
The underlying tech is simple—teams add YAML files to declare ownership of their codebases, and thanks to standardization, we know exactly where to look to grab that file and ingest it into our ownership database. This single system has saved us from countless hours of arguments over who owns what and has improved the quality of these systems by getting the right information to the right teams at the right time.
Yelp’s EE Journey: Part 3 – Best Practice
Our next phase occurred in 2017 when we had around 400 engineers and 40 members of the EE team.
The problem was the: “How do we give better observability of debt?” And maybe a question our execs were asking: “What is the value of the engineering work we are delivering?”
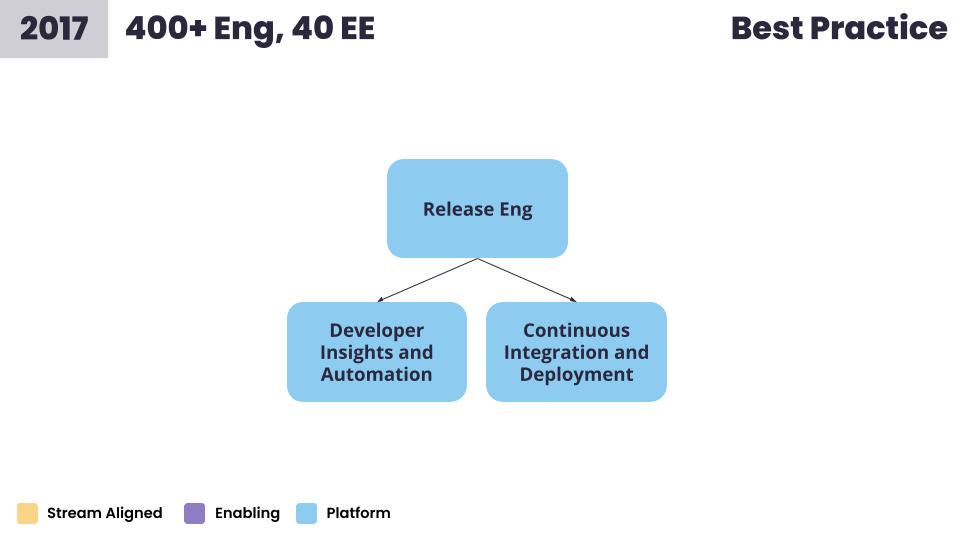
The questions we were asking and solutions we came up with at this stage included:
How do we encourage quality? → EE metrics.
You need to know what you’re doing for your organization and how you’re providing value. We showed we were providing value through the problems that we were solving incrementally as we moved forward. We also started to support EE metrics, a tool for surfacing debt and migrations to teams across the engineering org.
How do we understand Engineering Delivery/Performance? → Accelerate 4 key metrics.
We adopted the four metrics for engineering outcomes outlined in Accelerate: lead time, deployment frequency, MTTR, and rollback rate. We found that these metrics helped us understand whether we were headed in the right direction in the long term, but still needed to define supplemental metrics similar to areas that The SPACE of Developer Productivity suggests.
Below is a screenshot of a page that a team might see. Recently we have added a new section to highlight required migrations (migrations that are critical to the business’s success) so that teams prioritize those migrations over other less important debt.
The term “quality” is pretty expansive, and we try to capture a multitude of things: Do you pass your security checks? When you have an outage, do you write a post-mortem? Did you actually follow up on the action items from the post-mortem?

You can click on them to learn more and get instructions on what you might need to do for that migration.
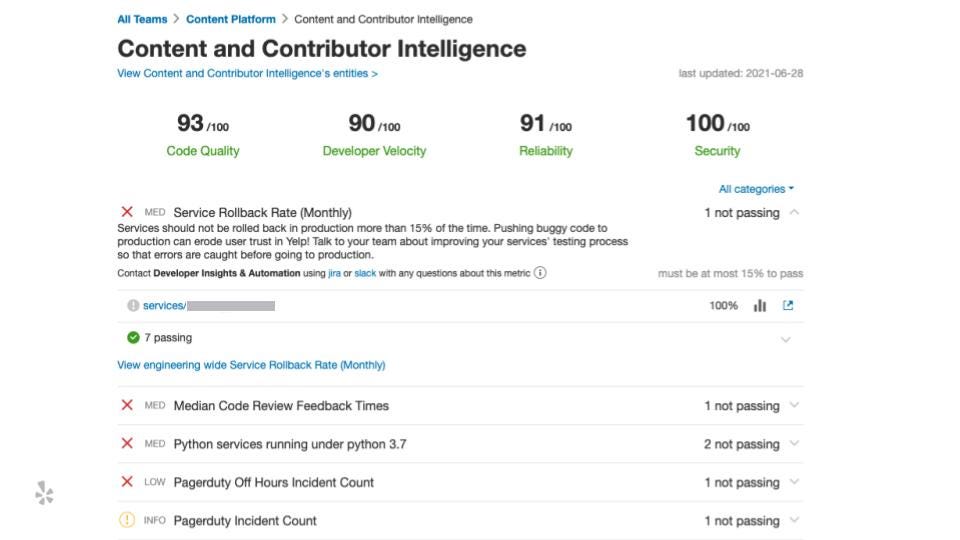
Everything is going into EE metrics and we’re able to provide a precise page for every team at different levels in the org hierarchy because of the ownership service we have.

Because of limited funding, we started creating these systems (EE metrics, Ownership) on the Release Engineering team. Today we have expanded this team into two: Developer Insights and Automation and Continuous Integration and Delivery. This allows for a concrete focused charter between the two. Ultimately, the usage of EE metrics has been a long road. We learned the importance of having leadership continually involved in metrics discussions. Honestly, it is something we are still working on. I would have never guessed how much time and effort we would have put into this system. It’s a lot of work!
Yelp’s Engineering Effectiveness Journey: Part 4 – Current State
This last phase began in 2022 and this is essentially where we are today. We have around 1,300 engineers and 70+ members of the EE team.
Today we have the benefit of time and the ability to be proactive. We continue to get feedback from our developers to answer the never-ending big question, how do we continue to accelerate workflows?
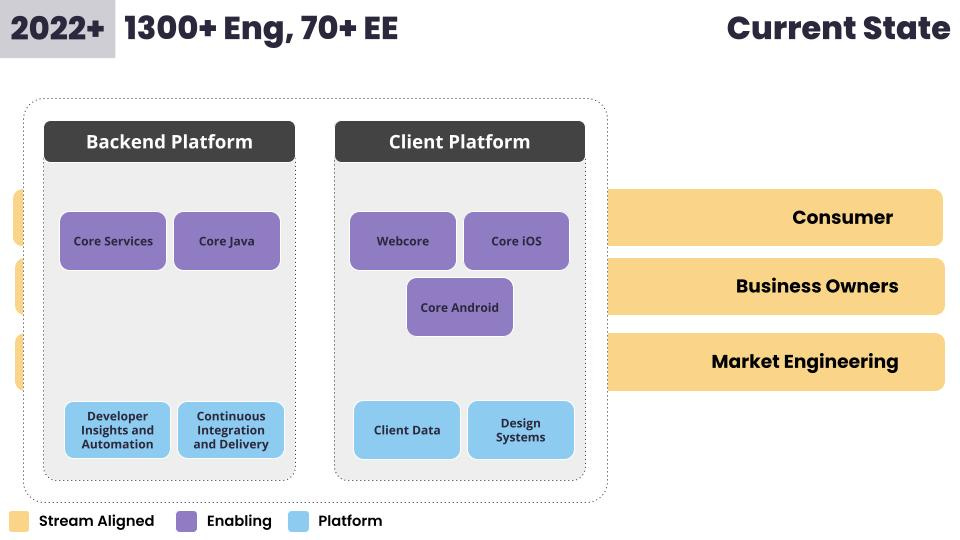
We’ve been able to focus on the following areas:
How do we better support web development by reducing the maintenance burden for teams? → Currently with a Platform as a Service, Gondola.
This helps us better maintain React code at Yelp by making data fetching easy and reducing the amount of boilerplate teams need to get a service up and running.
How do we help developers get the data they need across all platforms without writing code? → GraphQL.
GraphQL has been the right abstraction layer for us to manage our data fetching effectively across all of our platforms.
How do we provide better language support? → VSCode IDE Plugins such as integrating Jenkins output, internal documentation, etc.
How do we migrate faster? → More automation for code migrations, facilitating more than 4K dependency bumps and roughly 4K migrations automatically for teams.
The challenges that we’re continuing to focus on include: getting more adoption for our paved paths, automatic code generation to help teams with code maintenance, and considering how we might use LLMs to accelerate developer productivity.

Final Thoughts
Reflecting on our journey, it’s evident that the past often repeats itself. When switching paradigms like moving from a monolith to SOA and now to a monorepo for frontend support, we are now faced with seemingly familiar problems, like multiple engineers trying to ship code in the same code base. We had a reason for each move, though: the monolith increased in complexity due to a lack of code compartmentalization and SOA helped us divvy out the support for managing that code at scale with forceful code separation. New tech like Lerna helps us achieve that same functional separation while making it easier for us to update application infrastructure atomically.
Looking back at our progress, it’s been amazing how quickly teams moved out of the monolith and that it still exists today. In fact, we just wrote a blog post on how we migrated 3.8 million lines of Python to Python 3 even though only a fraction of developers still have to interface with the monolith. I wonder if Yelp should have bit the bullet and deprecated the service when it was a much more tractable problem.
Some final words of wisdom:
Jumping to the “latest technology” will create friction for your developers. Let the problems guide whether you need to migrate. Be sure to ask questions like: What problem is this solving? Am I trading one problem for another? And when will developers be able to realize the benefit of this switch? These answers aren’t always straightforward.
For Flow → Typescript, we spent years evaluating if it was the right time to switch. Flow does provide similar type-checking functionality, but when you dig in, you realize that the community support is waning. If you get an error in Flow, there are very few forums you can still go to to get support. This means that Yelp Engineers end up taking on this burden and new people joining have a tough time ramping up.
Check out Netflix’s Bruce Wang’s in-depth article on the migration trap.
Simplify your support burden so that you can provide value elsewhere.
We inherited a legacy i18n platform from a Product team. Some infra had support for real-time translations and other infra was a production-based system for fetching translated strings. We re-looked at the requirements for the system, deprecated the production system, and moved string fetching offline to be provided with the shipping application. This removed the on-call burden. In doing this, we also evaluated an external platform for getting strings from translators. All in all, we limited the surface area to a few scripts that have been 100% reliable and have removed us from the support loop. If we hadn’t simplified this system, we wouldn’t have been able to provide value to our web developers in terms of supporting React, server-side rendering, Gondola, Typescript, and much more.
Finally, my parting words for any up-and-coming EE leaders are: Focus on defining problems with input up, down, and across. Get alignment on those problems and don’t be afraid to ask for partners to help. Defining these long-term problems eventually hints at org-wide strategies and a clear long-term vision. All of these things help build alignment, minimize wasted effort, and showcase the value your organization brings to the table.
That’s a wrap - Hope you liked it!
Let us know what you think of this third in-depth article! Was it too long? Too short? Did it bring you value? Do you like the format? Was it actionable enough? What can we improve? We’re all ears 👇
Thanks in advance for the feedback!
Quang, Cofounder at Plato, on behalf of the Plato team
Great job 💕💕
Loved the article. super detailed.