


#8 - How we do Platform Engineering at Microsoft Viva Engage (Yammer) | Diego Quiroga, Principal Software Engineering Manager at Microsoft
Platform engineers: between the Yammer and the anvil.


Hello beloved subscribers, Quang here, as usual! 👋
Today, we’ll explore the ins and outs of Platform Engineering with Diego Quiroga, Principal Software Engineering Manager at Microsoft, working on Viva Engage, previously known as Yammer. He’ll explain why (and how!) you can shift from dependency to self-service models, why you should invest in troubleshooting tools, and how you can foster a culture of documentation and coaching. Let’s get started (after a quick self-promo) 👇

Diego Quiroga, a 20-year engineering leadership journey
What exactly is the role of platform engineering teams and what are their specific challenges? Before we get into all of that, let us share a bit about Diego and his background. We’ve known him for quite a while at Plato, where he’s been mentoring promising engineers for a few years!
Diego Quiroga is a Principal Software Engineering Manager at Viva Engage, the definitive social media app for the workplace, formerly known as Yammer.
“In the more than two decades I’ve spent as a software engineer, I’ve been dedicated to clarifying complex engineering challenges and ensuring that everyone in my organization thrives.”
Prior to Microsoft, he played pivotal roles at AWS, OLX, and Google, focusing on building large-scale distributed systems. Though they were not called “platform” teams at the time, he’s been leading core services/frameworks/applications teams since 2013 when he joined OLX.
In the more than two decades he spent as a software engineer, Diego has been dedicated to clarifying complex engineering challenges and ensuring that everyone in his organization thrives. He is a big advocate for continuous learning and at the moment, he is exploring topics like systems thinking, storytelling, and the future of engineering leadership.
Diego was hired at Microsoft in 2021 to lead a team in Vancouver, initially augmenting the capacities of the Core Application Platform team in San Francisco.
Later, the team split off on their own with a subset of the platform's services. After a subsequent reorganization, the team expanded its scope, incorporating many more foundational services, effectively doubling its surface area. Diego joined us at Plato Elevate’23 to share his leadership journey at Microsoft, and you’ll find his article below.
Check out Diego Quiroga’s mentor profile, or follow him on LinkedIn!
How we do Platform Engineering at Microsoft
From Yammer to Viva Engage
Viva Engage was born in 2008 as Yammer, under the premise of “working out loud.” The idea was that being transparent and public by default at work would help companies build stronger internal relationships.
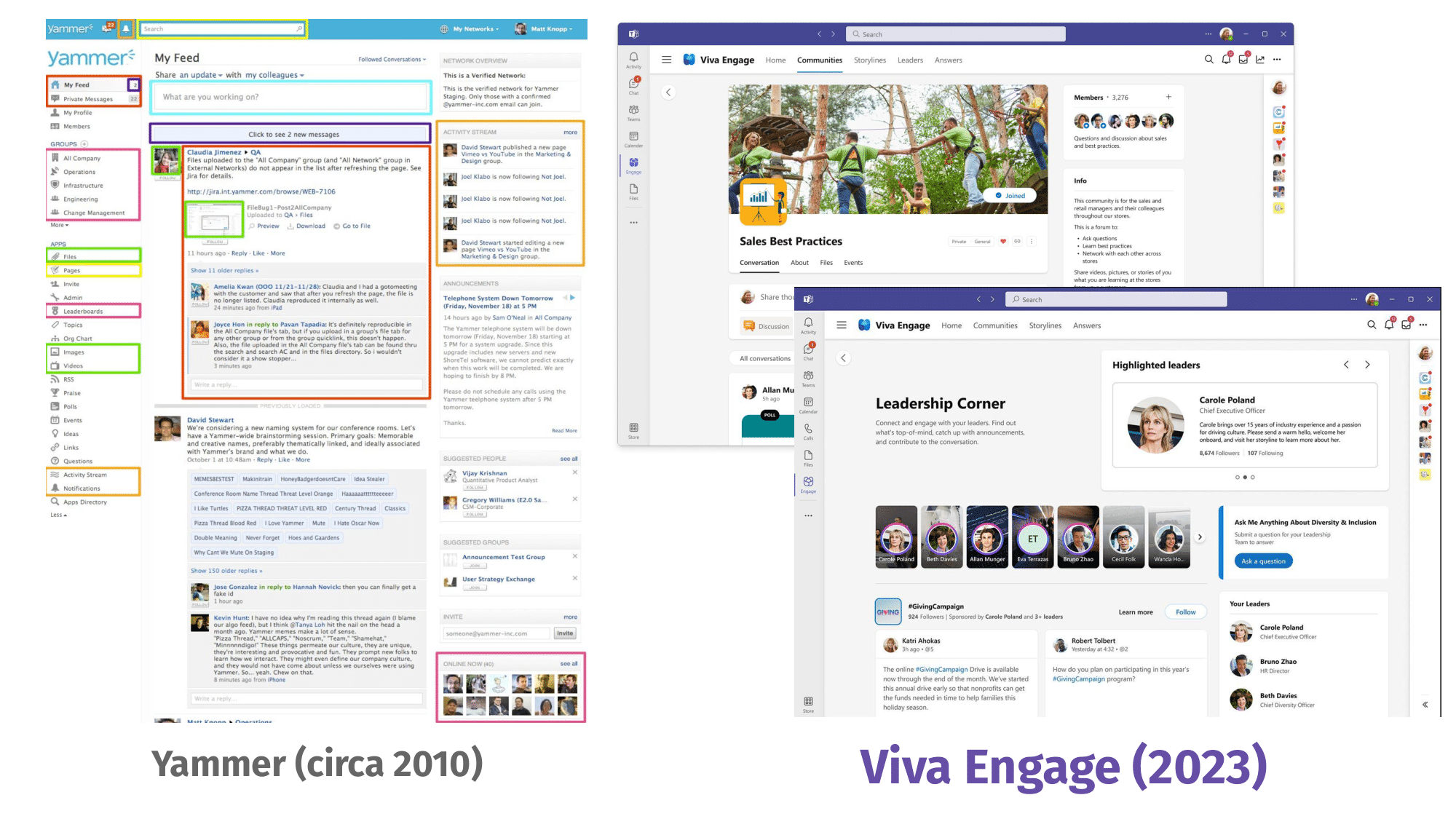
In June 2012, the startup was acquired by Microsoft. The integration with Microsoft Teams in 2019 and increased growth in demand for enterprise social networks around 2020 led to a full UI revamp, new offerings like Answers, and the rebranding in 2023 to Viva Engage.
Platform Engineering: A Primer
Platform teams provide knowledge, support, and the building blocks that feature teams use to ship business-facing functionality at a faster pace.
What do we mean when we talk about ‘platform engineering teams’? A useful definition is: Platform teams provide knowledge, support, and the building blocks that feature teams use to ship business-facing functionality at a faster pace. In other words, the mission of platform teams is to enable product teams to get things done.
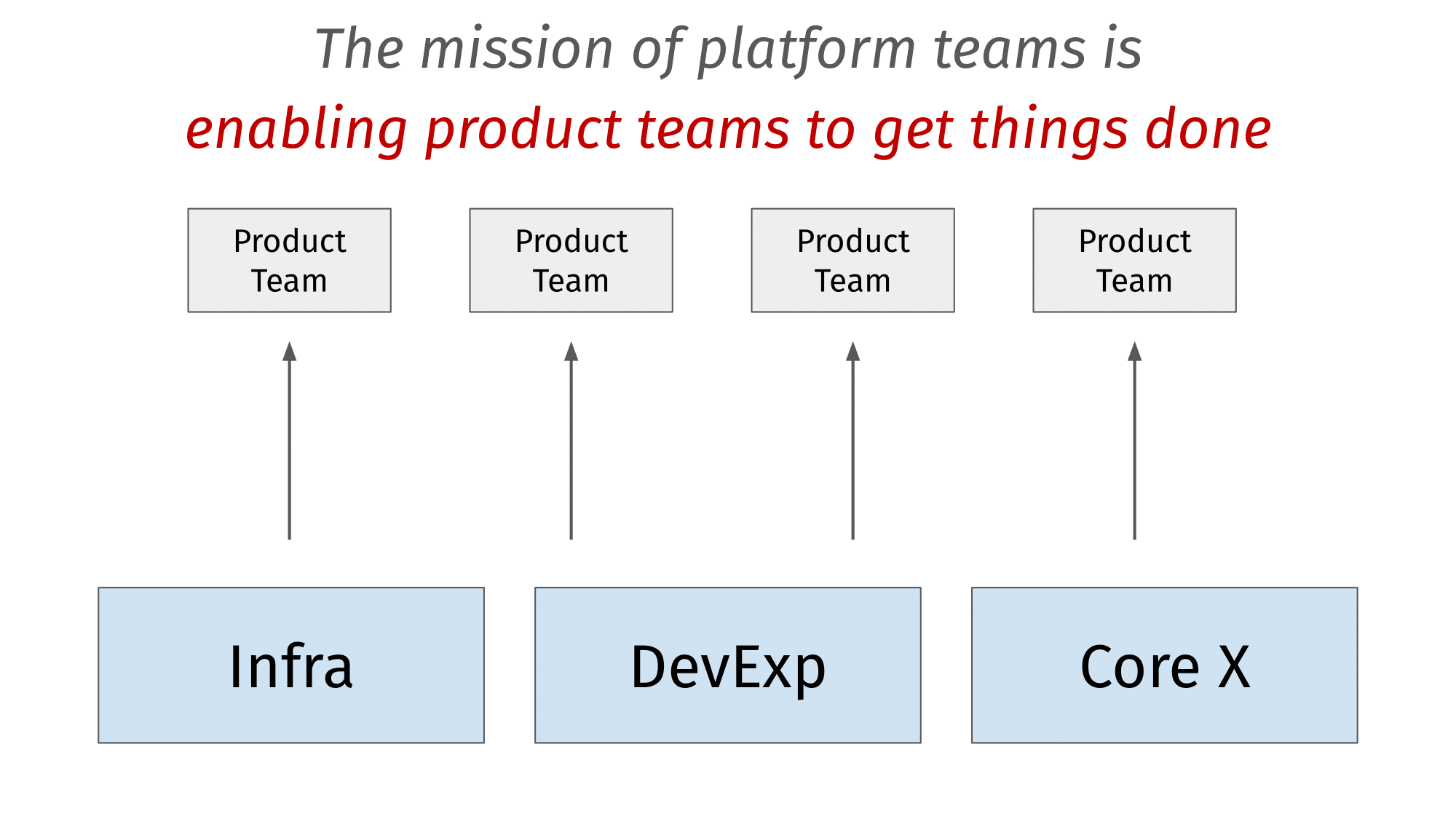
Platform teams are horizontal enablers of the business. For that reason, Infra, Ops, and DevExp teams can be considered in this category. Also, teams like mine, are built around a set of foundational backend services, with names like Core Platform, Core Frameworks, or Core Services.
There’s not always a clear line of distinction: Feature teams, as engineering teams, have a lot in common with platform teams. They both need to satisfy their customer needs, deliver under time and capacity constraints, and be mindful of their tech debt.
But some unique challenges set platform teams apart.

A few of the challenges specific to platform teams include:
They need to be one step ahead, making bets in their roadmap to have new capabilities ready by the time feature teams need them.
Tackling support requests while working on their own projects.
Catering to a captive audience with the same expertise—engineers like them. And that can become a double-edged sword at times.
The value of platform investments is not easy to explain to many stakeholders.
Having to deal with decisions, actions, and inactions that have long-term consequences and a larger blast radius.
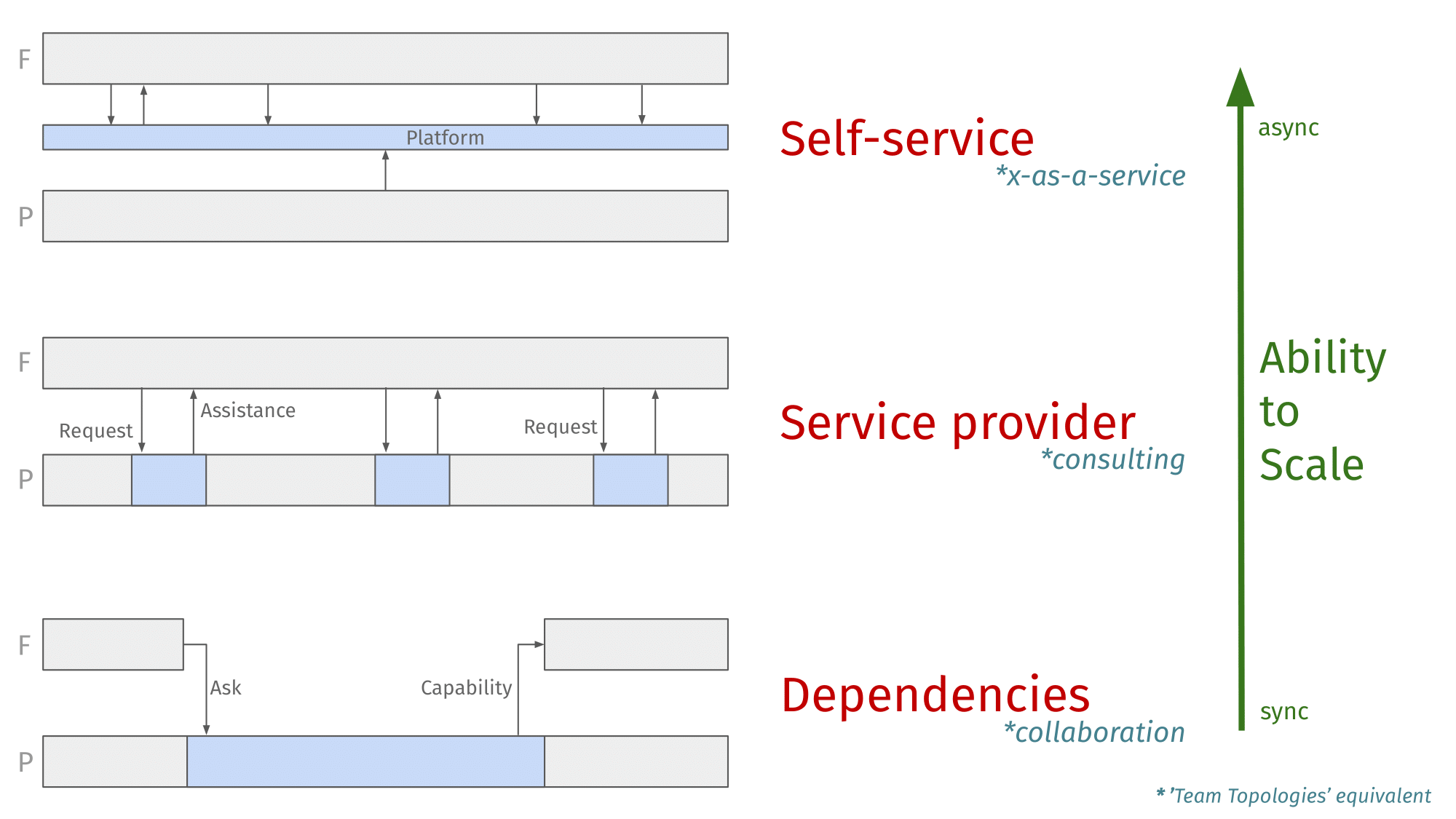
It is helpful to consider platform teams from a systems thinking perspective as it allows for a holistic understanding of how decisions and actions impact their processes and outcomes.
The most basic interactions with other teams—and likely the most expensive—are dependencies. When receiving requests from feature teams to build something, it requires time to validate each one for feasibility, roughly size, stack-rank them against org priorities, and address these requests.
On a different level, shorter, more focused interactions that are used to solve immediate problems or provide guidance can be characterized as following the service provider model. These types of requests will always be present for a platform team.
Finally, there’s the holy grail of every platform team, the self-service model. If you can dedicate enough capacity, you can build capabilities that are intuitive, documented, and automated enough that other teams can leverage them pretty much on their own.
It takes more than just technical chops to be a great platform engineer. One of the most important qualities is user empathy. You've got to understand and respect where the users are coming from, especially when platform issues crop up. It's about being mature and coaching other engineers in a way that builds bridges, not walls.
You also have to be a clear communicator. You should be able to break complex stuff down so anyone can get it and produce top-notch documentation because it's key to enabling other teams.
Finally, the key to success for a platform engineer is the ability to stay focused, even in the face of a lot of distractions. Everyone wants a piece of your expertise, but you need to balance those demands with your high-level goals. It’s a lot to take on!
A Platform Team Journey
Now that we’ve established a baseline of what platform teams do, let’s take a closer look at the evolution of our platform engineering team practices at Viva Engage.
Our team owns a set of backend services and components just above the bottom of the stack. In a sequence diagram, you would find our services as downstream dependencies for pretty much everything else. These services are leveraged by teams building features on top of them like Communities, Live Events, Storyline, Campaigns, Leadership Corner, Answers, and many more.
Two years ago, the activity of any given day for the platform team was frenetic. There were some people solving performance and reliability issues. Others were working on new product features as part of temporary crews, and each one of them was cycling through a heavy on-call rotation.
The team also handled a steady stream of PR reviews and requests for assistance on all kinds of things. On top of that, they were invited to meetings for consultation all the time. In the best cases, teams reached out well in advance, but in most cases, they rushed at the very last minute to obtain the blessings of the platform team.
Even when all this activity was really valuable, this hectic situation increased the risk of overworking people or missing breaking or performance-impacting changes.
And while the platform team was appreciated for our contributions, we struggled to deliver on our commitments. It was not easy to find the capacity to improve our operational health, and some of those efforts had to be piggybacked opportunistically on feature teams’ projects.
What we tried, part 1: Tracking inbound requests and leveraging analytics
In our first iteration to improve things, we tried a few things. Among them was introducing more rigor in the way we handled inbound requests and leveraged analytics.
We created guidelines for people doing the triage and automated tracking in our ticketing tool to get a real sense of volume, turnaround time, most demanded topics, and most demanding teams.
What we tried, part 1: Formalized regular, structured office hours
We formalized office hours to discuss future project needs. It was nothing too fancy or sophisticated—for every booking and depending on the topic, I manually invited the best-suited SMEs from the team. With a minimum lead time of 48 hours, it made it easier to review materials shared by our colleagues in advance.
What we tried, part 1: Promoting the best ways to engage with the platform team
Finally, we used every opportunity to “educate” the rest of the org about our domain and the importance of involving us early on in the planning cycle. I posted reminders across multiple communities, reached out to EMs and PMs, and even hijacked time in meetings to explain the way user flows depended on our services.

Tracking inbound requests gave visibility to an important part of our workload.
Results from our first iteration
Tracking inbound requests - SUCCESS!
Office hours - Mixed Results
Educating the rest of the org - FAIL
The results of this first iteration? Tracking inbound requests in our ticketing tool was great. By putting the data in a dashboard, we confirmed the volume week over week was heavier than anyone suspected.
Surfacing this information paid off in many different ways. It made us better at chasing lingering requests at the tail end of our time-to-response curve. And it was very useful to show impact when discussing allocation with our leadership team.
Office hours were a mixed bag in terms of results. Yes, some teams took the opportunity to provide context in advance, and that made those conversations much more productive. However, the volume of “impromptu consulting” did not decrease, and members of the team continued being bombarded by direct messages (DMs) from those looking for a shortcut.
When it came to educating the rest of the org, I found very limited success explaining and promoting our capabilities in my roadshow through the organization. Not much changed at this stage and my attempt made little difference. I believe this was due to the fact that the concept of a platform team was not clearly established or understood.
Before the next iteration, we delved deeper into the ways we collaborated with others, aligning our actions and investments towards self-service solutions to scale our impact.
What we tried, part 2: Using playbooks and coaching the platform team
In this next phase, we started another awareness campaign, where we made our ownership very clear and explained what would be the most appropriate mechanisms of communication for any given need since we use multiple channels for teams to engage with us.
For starters, our own Viva Engage communities were great for self-contained requests and longer conversations. We also use Microsoft Teams channels for live assistance whenever we launch a new offering. We constantly coached other teams to reroute every single assistance request to public channels. This helped keep platform engineers from being constantly randomized. Plus, a solution given to one person in a public channel helped the next one, hence reducing our workload over time and making the org more knowledgeable as a whole.
What we tried, part 2: Creating paved paths with templates and how-to guides
We also began creating how-to guides and templates for the product, application, and feature teams and playbooks to guide the platform team in their interactions with these other teams.
We doubled down on office hours, with an emphasis on capturing the decisions made there in our wiki so they were searchable by anyone. In doing this, we detected inconsistencies in our guidance. We had several implicit assumptions that were not quite correct, so we documented the right ones, again, in the wiki.
I coached the team to use DMs as opportunities to train the org and redirect longer conversations to office hours. Some of them were concerned about impacting personal relationships, so we role-played a few situations for everybody to be comfortable doing it.
Examples of those situations included:
What if someone asks for an urgent answer on X?
What If someone demands a troubleshooting investigation we believe is not for us to perform?
What do I do with constant DMs by one very insistent individual?
What if they bring up their manager, PMs, and others in a conversation to make their case?
What if a matter is not fully solved and requires follow-up conversations involving other SMEs?
The goal was to help them handle the pressure to act on something just because someone said it was critical and adequately push back when appropriate.
After that exercise, we created playbooks for the team, with scripted responses for the most common requests and examples taken from the best interactions.
Looking back at the evolution of office hours, we felt it was important to replace the ad hoc conversations that were taking place with the platform team. Even if these conversations were scheduled, the results from them were never captured. This meant that important decisions, agreements, and trade-offs were lost forever and neither the parties involved nor other engineers could access that vital part of information.
We changed our approach to office hours mainly in two ways: First, by being very strict on redirecting every single ad hoc request to an officially booked office hour. Second, by recording those conversations and capturing the conclusions in our wiki. This allowed us to detect inconsistencies in our guidance, what engineer A expert on service X recommended was different from what engineer B believed was right. Clarifying those assumptions led to improvements in our guidance and how-to wikis for other teams.
We also began looking for ways to document our work and make it more scalable. We tried to reply to every question with a documented answer in what eventually became a knowledge hub for feature teams. We also created how-to guides for common tasks with the intention of automating manual steps somewhere in the future.
What we tried, part 2: Investing in troubleshooting tools to offload work
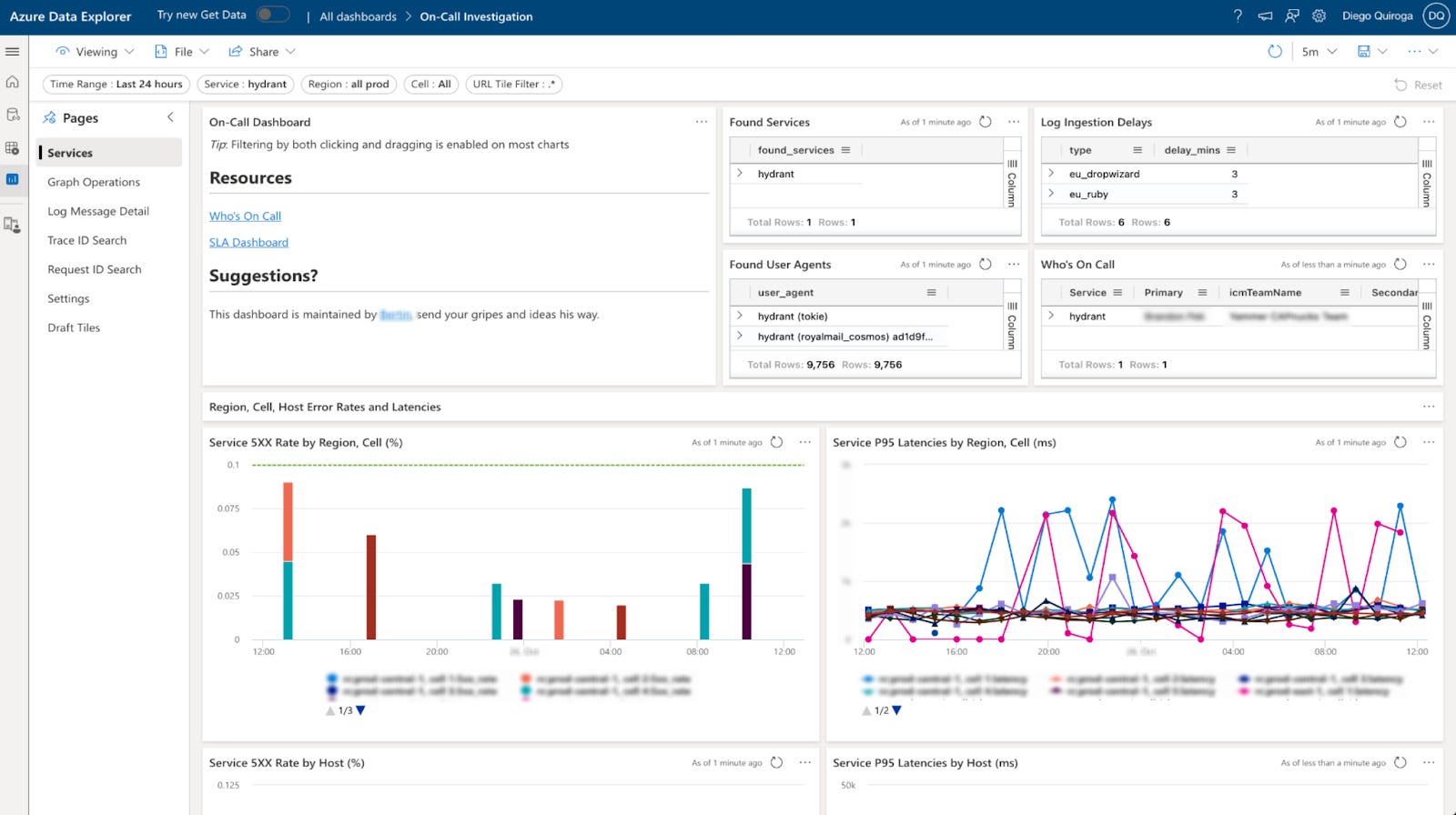
We also invested in troubleshooting tools. We looked into the most time-consuming requests, asking open questions like, “Why does this not work as I expected?” or “What is making my operation slower?” For that, we created troubleshooting and self-diagnosis tools that we pushed every chance we had. The tools were so useful that many adopted them and now we have contributors from all over and extensions we never thought of.
All of these tools are very contextual to our company, product, and domain, but here’s a quick overview. We built multiple dynamic dashboards utilizing Kusto (Azure Data Explorer) validation tooling including:
GraphQL Tracing and Errors Troubleshooting
Services SLO and Budget Error Consumption
Migration Progress (showing adoption of v2 over v1 in traffic/teams, performance improvements of v2, and other related metrics)
Tracing and Troubleshooting for a grid of hundreds of interconnected microservices
Results from our second iteration
I think what made us successful was to be very pragmatic and not dogmatic or prescriptive in our approach to producing guidance for other teams. We were also consistent in preserving the necessary capacity to work on this task instead of having it be an afterthought.
Observing the external requests or “dependencies” in our planning lingo, there has been a marked difference in what was asked, from 15 asks every quarter being “build X for me” to 10 or fewer that are now phrased as “provide assistance for us building X.” This is also reflected in capacity allotted to dependencies, from over 50% to 20% or less.
Over time, we learned that we had to change and evolve as much as anyone else. Gently but firmly—and with a lot of nudging on our part—we experienced tangible results. Without it being one of our goals, the quality and thoroughness of our inputs improved. Needs were now more clear, concise, and consistent and conversations were much more productive.
Our success proved we could take more. And more was given to us in the last reorg. Our surface area doubled after taking ownership of more platform services.
Now What?
Our team's landscape today looks different. Quarter after quarter, we see the shift from “please build this for me” to “guide me in using this on my own.”
We’re moving further from the dependency model and closer to the self-service one. But we still have plenty of work to do.
What’s keeping us busy these days?
Simplification
Offloading non-critical tasks
Feature teams owning their QoS
Increased visibility.
Simplification for customer features that look small in appearance but can be labor intensive. We are reducing this complexity by reallocating responsibilities to reduce the number of services impacted.
For some of our codebases, we ran a champions program to entrust a few individuals on every team to review and approve PRs on their own. Champions are heavy users of the platform, knowledgeable and trusted to augment the codebase on their own and code review for others. They are either recognized as such by our platform team or are proposed by their teams and vetted by our SMEs. Champions reach that status by their involvement and commitment to keep platform services healthy, augmenting it with great quality code, and contributions to developing others like them. In some cases, they acquired their expertise by temporarily joining one of the platform crews to contribute to a small project. In one of those cases, it reduced our interventions by almost 50%.
As we are not a rebranded SRE team, nor do we intend to become one, part of our role today is to help feature teams understand and act on reliability and performance on their own.
New product features can be made exciting during demo days. Try that with a deprecation or a latency reduction of 15%. We keep looking for creative ways of explaining the value of platform investments and preserving the capacity required to keep things healthy.
Looking further into the next few years, we keep alive the aspirational goal of scaling and white-labeling our offerings for them to be used by others at Microsoft. That implies making our capabilities generic and configurable enough to be able to power other Microsoft products expanding our ‘customer base’ beyond Viva Engage.
We continue iterating, focusing on high-leverage activities as much as we can, and learning from our experiences.
Wrap Up: Learnings
As a quick recap: We discussed the nature of platform teams' work and some ways to make it better. One recurring theme was the challenge of capacity—how do we manage ever-growing demands with limited resources? The answer isn't just about increasing headcount but optimizing processes, encouraging self-service, and continually evolving based on feedback.
Takeaways:
A platform team's strength is not just in what they build, but in the practices they adopt, the tools they provide, and the culture they cultivate.
Focus on reducing toil, leverage comprehensive documentation, and self-service to scale your impact without growing your team linearly.
Recognize that each request is not just a task, but an opportunity to teach and drive toward self-sufficiency.
Great platform teams can tell a good story about what they have built, what they are building, and how they make the overall engineering org more effective. And that is an essential survival skill.
The more capacity you create, the more you can do to enable other teams. You will never run short of work to do; make that your top priority.
Hope you enjoyed Diego’s insights!
If so, you can share this newsletter with fellow engineering leaders:
And one quick question this week:
Cheers!
Quang & the team at Plato
Looking forward to future iteration readouts, thank you Diego + Quang!