


#16 - How to go from slipping to shipping | Manu Gurudatha, Sr Director of Engineering at PagerDuty
When improving efficiency is your (Pager)Duty.



Hey everyone! Welcome to another issue of Plato’s in-depth guides for Engineering Leaders. This week, we’re welcoming Manu Gurudatha, Senior Director of Engineering at PagerDuty. He’s shared his insights on going from “slipping to shipping“ at Elevate’23, and made a detailed article from his talk. But first, some big news for Elevate 2024.
New speaker announced: Stripe’s CTO David Singleton

We're excited to announce that David Singleton, CTO at Stripe, will speak at Plato Elevate 2024 in San Francisco on June 5-6. Stripe's engineering culture is one of the best, and David helped shape its well-earned reputation. In 2020, David opened our virtual Elevate Conference and dropped the curtain on a few internal processes, including incident management. We're thrilled to have him back on stage, in person this time!
With this out of the way… Let’s dive into our article of the day!
Manu Gurudatha, two hats and a passion for wisdom
Manu Gurudatha wears two hats at PagerDuty: he heads the Incident Management Engineering Department while transforming Operations to make the company processes most efficient.
Before that, he led product development organizations in several companies, ranging from Series A startups to giants like Salesforce, where he managed the engineering for their Health Cloud unit. With his previous experiences, Manu has a proven track record of building strong products and platforms, sometimes from scratch and scaling those to sustain performance for thousands of customers.
Besides his impressive curriculum, Manu is a philosophy buff, which makes it a match made in heaven with us at Plato 👴🏻
We share his passion for wisdom, and we’re thrilled to have him share his insights with our mentees every week — or to a wider audience through Elevate or in the following article. In this guide, he'll walk you through his detailed process for enhancing team productivity, offering practical steps to transition from a state of slipping to one of successful shipping.
You can follow Manu Gurudatha on LinkedIn
How we went from Slipping to Shipping Products at PagerDuty
Quick question: How do leaders or stakeholders stay informed about the status of an in-flight initiative or project at your company?
Option 1: Reports/dashboards/workflow automation
Option 2: Recurring meetings
Option 3: Periodic status reports
Option 4: Program manager/liaison
There’s no single right answer here. When I polled the audience live at Elevate, there was a good spread across different mechanisms for keeping stakeholders up to date.
In this article, I’ll explain how our status reports helped us uncover a major issue with slipping and the steps we took to address it — in other words, how we went from slipping… to shipping.
First, a brief introduction to me and my work at PagerDuty. I’m Manu Gurudatha and I’m the Senior Director of Engineering for our core incident management product at PagerDuty. I have over 18 years of experience in the B2B SaaS environment across smaller startups and enterprise companies. Most recently before PagerDuty, I was at Salesforce.
PagerDuty’s mission is to revolutionize operations and build customer trust by anticipating the unexpected in this unpredictable world.
We are a public company. We serve over 1 million end users across 26,000 customers. Two-thirds of the Fortune 100 companies are our customers.
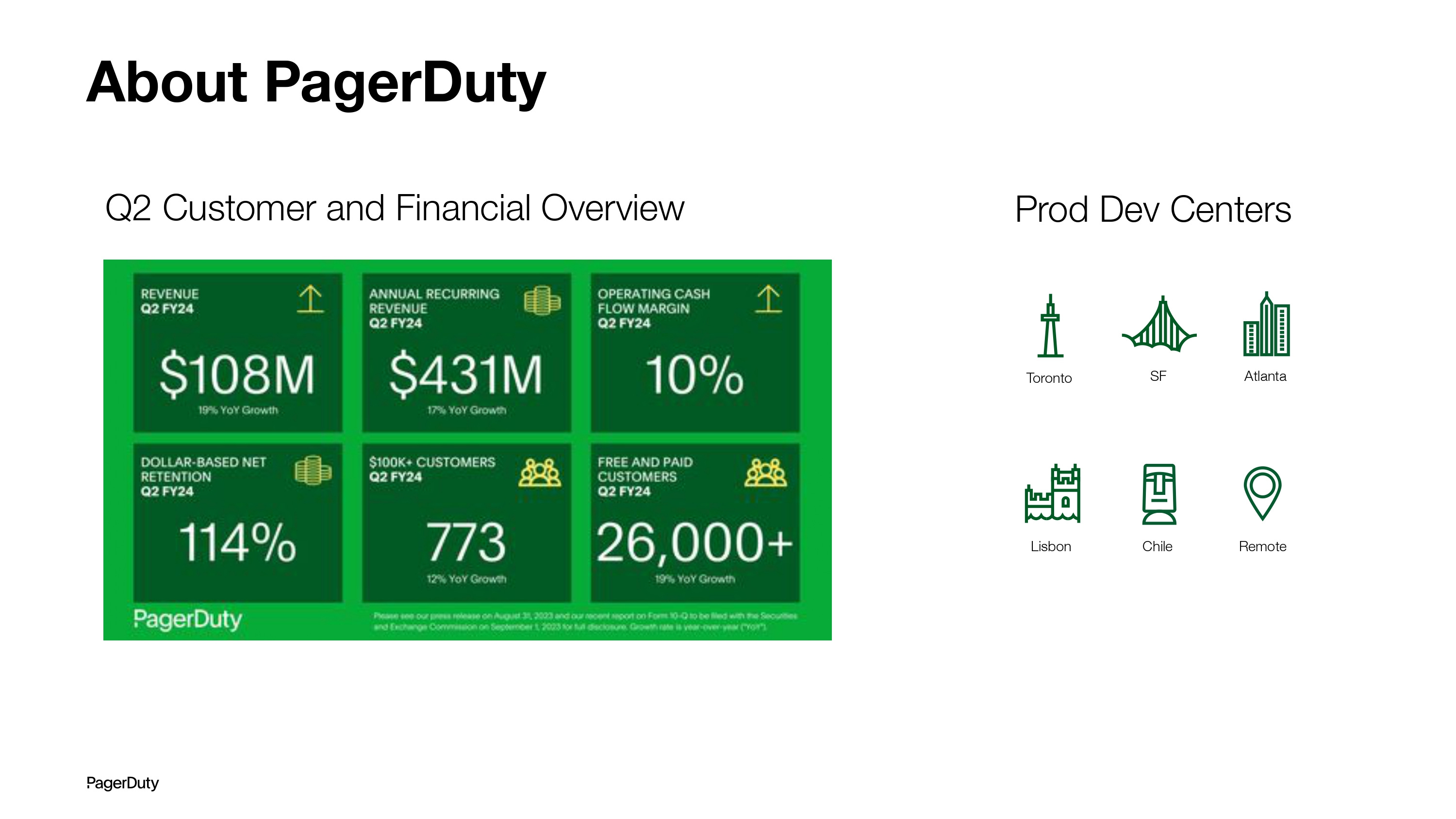
Our product development hubs are distributed. We have centers in San Francisco, Toronto, Atlanta, Lisbon, and Chile, and we have a sizable population outside of these hubs that work remotely as well.
Our engineering team consists of ~75 people, including directors/managers and staff engineers, and the business unit (including product managers and designers) has about 100 people in it.
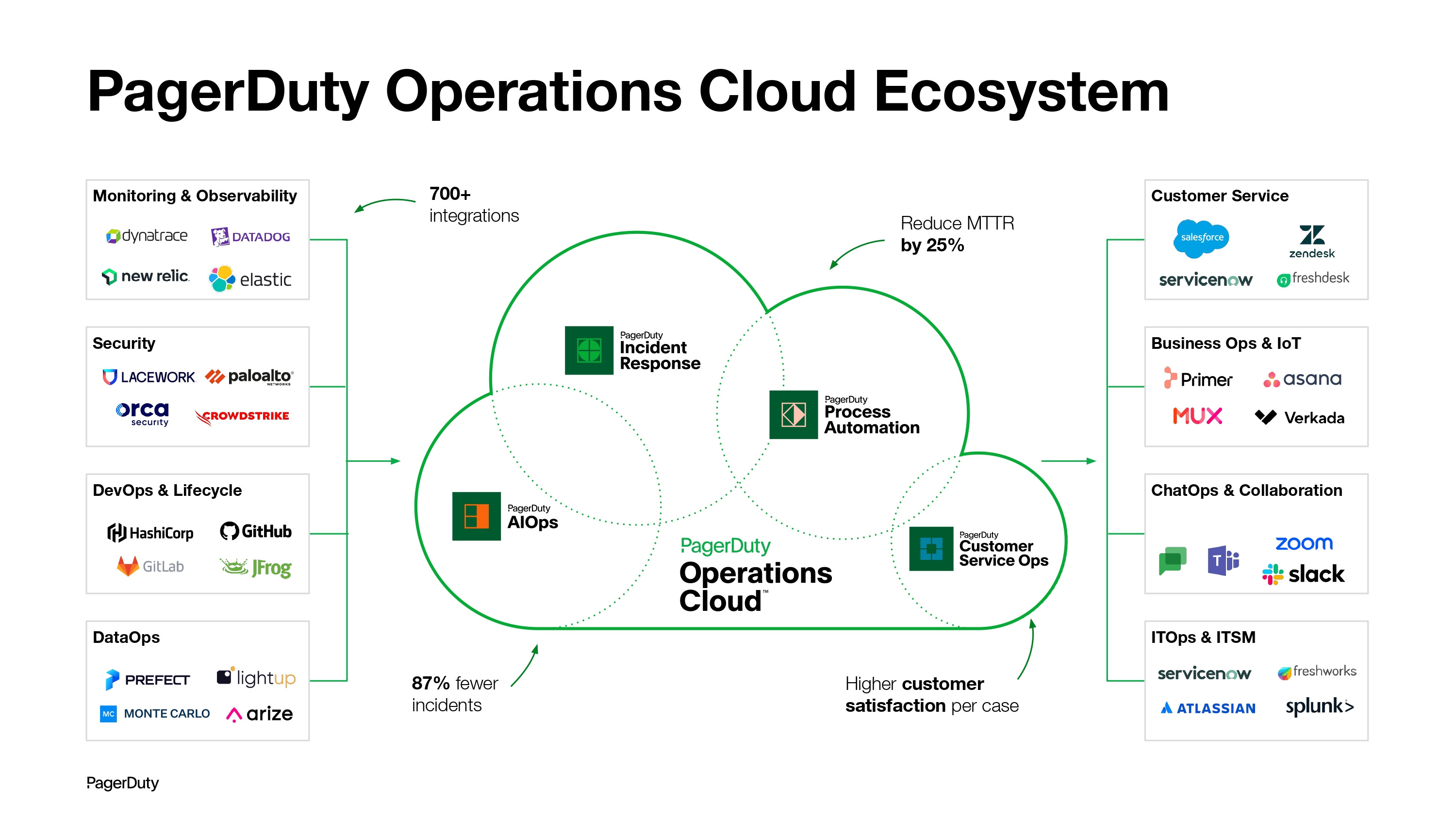
The PagerDuty Operations cloud is the AI-powered platform for automating and accelerating mission-critical operations. We have over 700 integrations (I’ve included a few on the slide above). Through this, we create 87% fewer incidents, reducing the mean time to resolve incidents by 25%. And within our CS Ops product, we are able to deliver higher CSAT scores as well.
The problem: slipping
I mentioned earlier that at PagerDuty we use status reports to keep our leaders and stakeholders informed of our progress.
For us, a status report is a Google doc that we all collaborate on and send it out to the company every two weeks. It’s cross-functional and received by the whole company. It allows us to engage with leadership asynchronously, and to answer questions that might arise.
You can see the format of our status reports described in the slide below.

I want to draw attention to the “slip.” This is a change from the original commitment date. We still include these dates, but put a strikethrough and update with the new date. See a real-life example in the slide below.

In the example above, the project had slipped more than seven months, impacting both the early access date and the general availability date.
This was a problem. Why? When we couldn’t ship according to schedule, it led to a lack of trust internally and with our customers. This eroded their confidence in us since we weren’t keeping our word.
For me, trust has two separate components:
Intentionality (Are we trying to do the right thing?): this was mostly intact, luckily.
Confidence (Do stakeholders believe in what we are saying?): this is where we were falling behind, due to constant slippages.
Based on my prior experiences, I saw it as a red flag that our organization could not ship consistently. That’s why I decided it would be the biggest area for us to solve, and took ownership to make it happen (after validating with my executive leadership that transformation was needed).
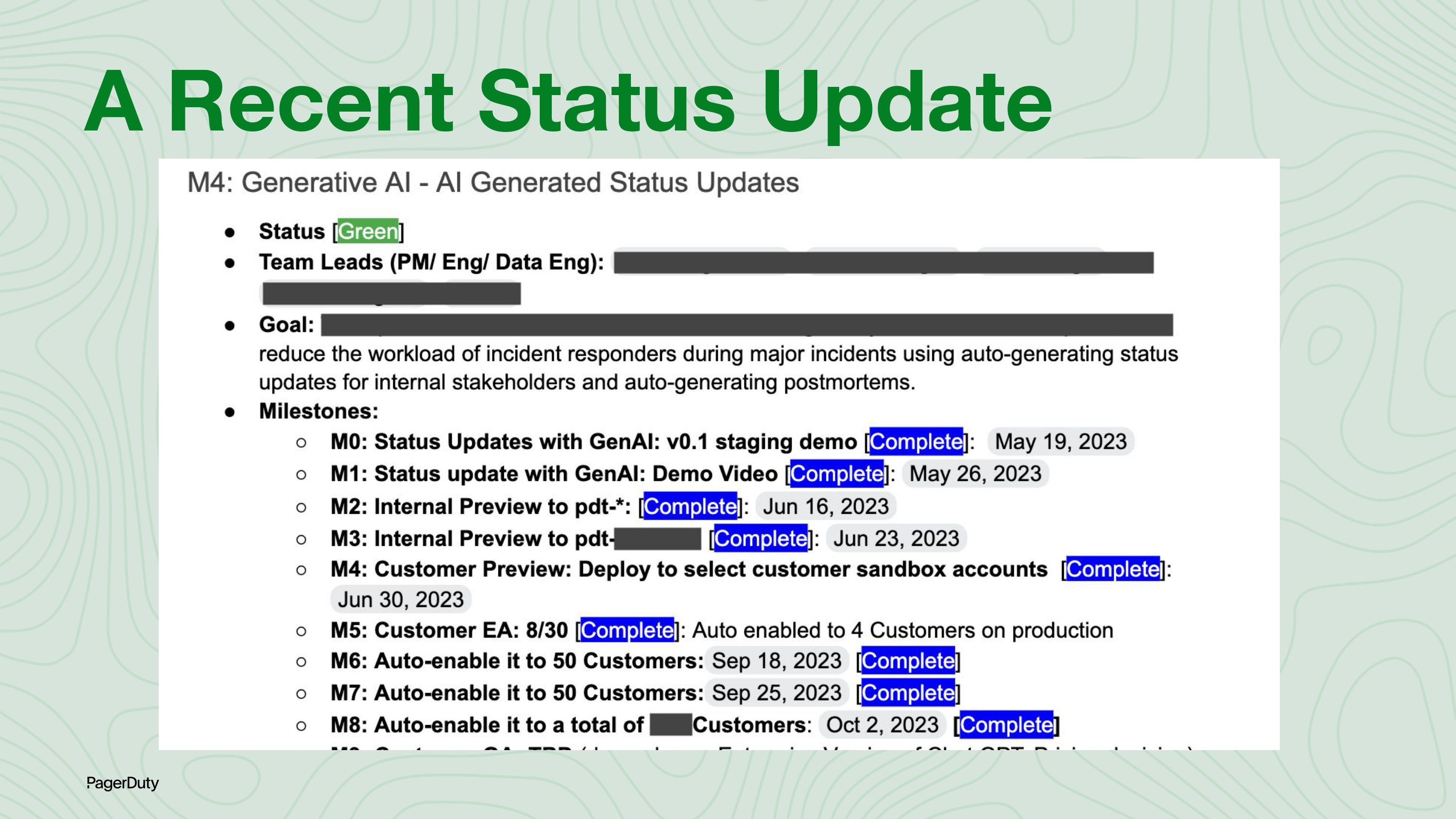
While the example above was from a few years ago, I also wanted to show you a more recent status update. I specifically chose the example below, which features generative AI, because there were a few more unknowns involved. As you can see, we were able to ship this very fast by breaking it into milestones.
Here’s another example where there are strikethroughs, but they swung in the other direction: we were able to ship earlier than we had committed!
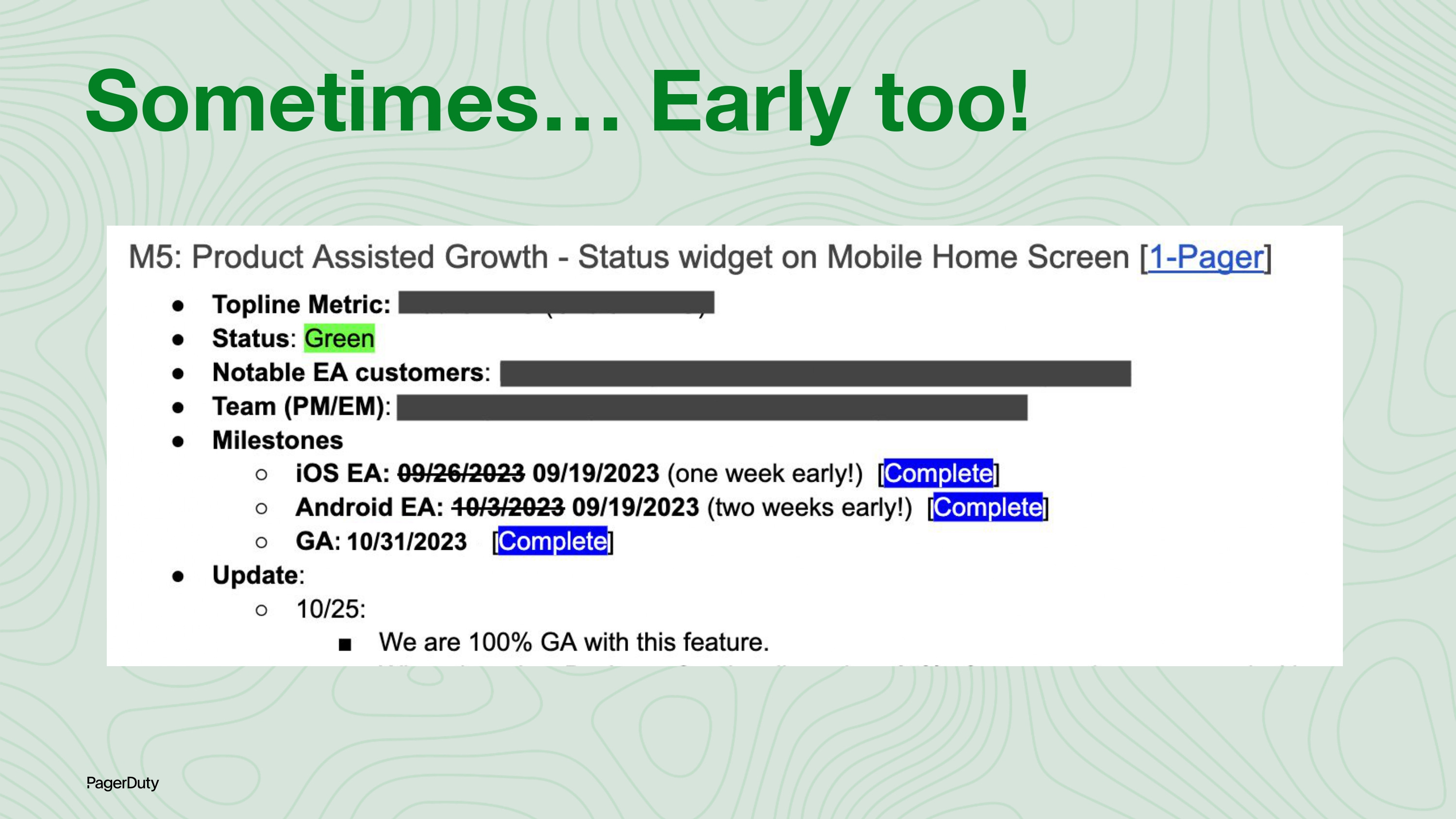
So, how did we transform this slipping to shipping consistently? Let’s dive in!
The 3-step process to go from slipping to shipping
The steps we took can be broadly classified into three main buckets: assessing and building trust, defining the future, and resetting to execute. Here’s a quick overview of each step.
Assess and build trust
We started by understanding the contributing factors. We assessed all the factors that were influencing delays and came up with hypotheses.
Define the future
We set a vision of what good looks like so we could work backward from that. We also had to transform our culture to make that happen.
Reset to execute
Finally, we reset how we worked by informing the teams accordingly and creating many frameworks and process improvements to enable that.
Now let’s take a closer look at each step.
1. Assessing & building trust with the team
First, we had to understand what was broken.
This was a crucial step because we faced a multi-dimensional problem and wanted to solve it holistically, rather than in a piecemeal fashion. A few key issues emerged.
Tech stack
The tech stack was 13+ years old. On the front end, we had Backbone and Amber and we decided to move to React. That migration was halfway through. On the back-end we had Ruby and Elixir, then we moved to Java and there was some Python as well. And from a data pipeline perspective, we rearchitected that and we were migrating to Snowflake. We also started with a monolith—as every other company does—and that became a giant monolith at some point. Then we shifted over to microservices. What we ended up with was a giant monolith with a lot of fragmented microservices, which was causing a lot of inconsistent experiences with the developers as well.
Team size and skills
Our team size was too small and teams didn’t have the right distribution of skills.
First, some teams weren’t “well-formed”, making it hard for people to work together. In most cases, teams consisted of 3 people. You can imagine what might happen when one of them goes on PTO when an incident arises: another team member must deal with a fire on their own. That leaves only one person to run the project. In such cases, you can say goodbye to your sprint plans… or any other plans you have at that point.
Second, some teams had only junior engineers, while others only had backend engineers, etc. Skills weren’t distributed in the right manner, making it difficult to progress.
Finally, in terms of culture, there was a lot of focus on autonomy, which is a great thing; but we were lagging behind in terms of alignment, especially with the Product team, and also the organization at large. This created friction that made slipping inevitable.
Tech debt
As explained earlier, given that our tech stack was a 13-year-old monolith we under-invested in, we had accumulated a lot of product and technical debt in the previous years, which created several issues, making it more difficult for us to ship in time. Getting predictability on a system riddled with a legacy tech stack without continued investment to address them was more than challenging.
Lack of prioritization
A lack of prioritization was also holding us back. We were operating with the following mindset: everything is important and urgent, which didn’t work well with many of our competing priorities.
Once we’d identified the core issues, we started defining what good should look like and comparing the delta between what we had and where we needed to go. Then, we needed to validate these hypotheses with our internal stakeholders and ensure we got their feedback.

We were also very intentional about building trust across all stakeholders. For example, we shared written plans with leaders so that they could engage with them way more efficiently, ask questions, and debate with us.
Similarly, we got feedback from our peers to ensure we didn’t miss anything.
Also with our direct reports, it was important to discuss and debate since they were the ones who would be carrying these things forward.
Across the org, we ended up over-communicating. We repeated the what and the why. As the saying goes, a message has to be repeated seven times before it can be heard and understood.
This allowed every stakeholder to get the context and direction of where we were heading.
We were then ready for the next step.
2. Define the future
Next, we wanted to set a clear goal for how things had to be done, and how we would hold ourselves accountable. This would’ve allowed us to start working backward and make the appropriate short-term trade-offs.
Setting a clear, understandable goal
One important execution goal we set (based on the Pareto principle) was: We are not going to slip in more than 20% of the projects a year. And when they slip, they won’t slip by more than 20% of the original time estimate. This was a simple, understandable goal that we set and repeated to make sure everyone was aligned.
We are not going to slip in more than 20% of the projects a year. And when they slip, they won’t slip by more than 20% of the original time estimate.
We chose a familiar concept (“80-20”) to create easier alignment while making it sustainable. Had we decided to make it 60%, it would have felt… half-baked. And 95% would have been unachievable in a sustainable manner.
Giving better estimates
One reason why we slipped so often was that our estimates weren’t always realistic.
The first order of problem to solve was thus to improve Predictability: giving estimates that were as close to reality as possible — so that we could focus on efficiency.
One of the caveats we identified was that engineers were too optimistic: they had high trust and good intent, but they were struggling to get things done in time, in this bottom-up environment. They were thinking about their tasks in terms of development and execution, overlooking everything beyond code: testing, integrating, validating assumptions, reducing tech debt, getting reviews from peers, etc.
Another reason was that they were afraid of sandbagging (underpromising and overdelivering). Every organization tends to underestimate the time to complete large projects (eg. infra/construction/major project shifts or migrations), both in terms of cost and time. We wanted to acknowledge this upfront and create a psychologically safe environment so that quality wasn’t compromised to meet deadlines. We thus arbitrarily asked every team to increase their estimates by 50-100%: this made the estimates closer to reality, based on previous velocity metrics, and flipping it back to teams increased accountability.
Defining rules of thumb
Once we set goals and improved estimates, we put a simple mechanism to keep us on track: get your “say:do” ratio as close to 1 as possible.
Get your “say:do” ratio as close to 1 as possible
Putting your goals in a SMART format is useful to achieve this. At PagerDuty, we use V2MOM, which is derived from Salesforce, but OKRs also work well. The point is that putting your goals in a SMART format is an important step.
Once you do, mechanism 2 is: “do what you said you were going to do”. This mechanism allowed us to drive accountability and push decisions down to the individual teams, thereby maintaining their autonomy, but crucially bringing predictability and alignment in the same process.
Mechanism 2 is: “do what you said you were going to do”
The slide below shows an actual say:do ratio for incident management for last year. You might notice that even at the end of the year we did not achieve everything we initially set out to do. But that’s a bit of a prioritization discussion: the focus was to make sure we would respect our committments. Reducing the scope and prioritization is a different beast in itself.
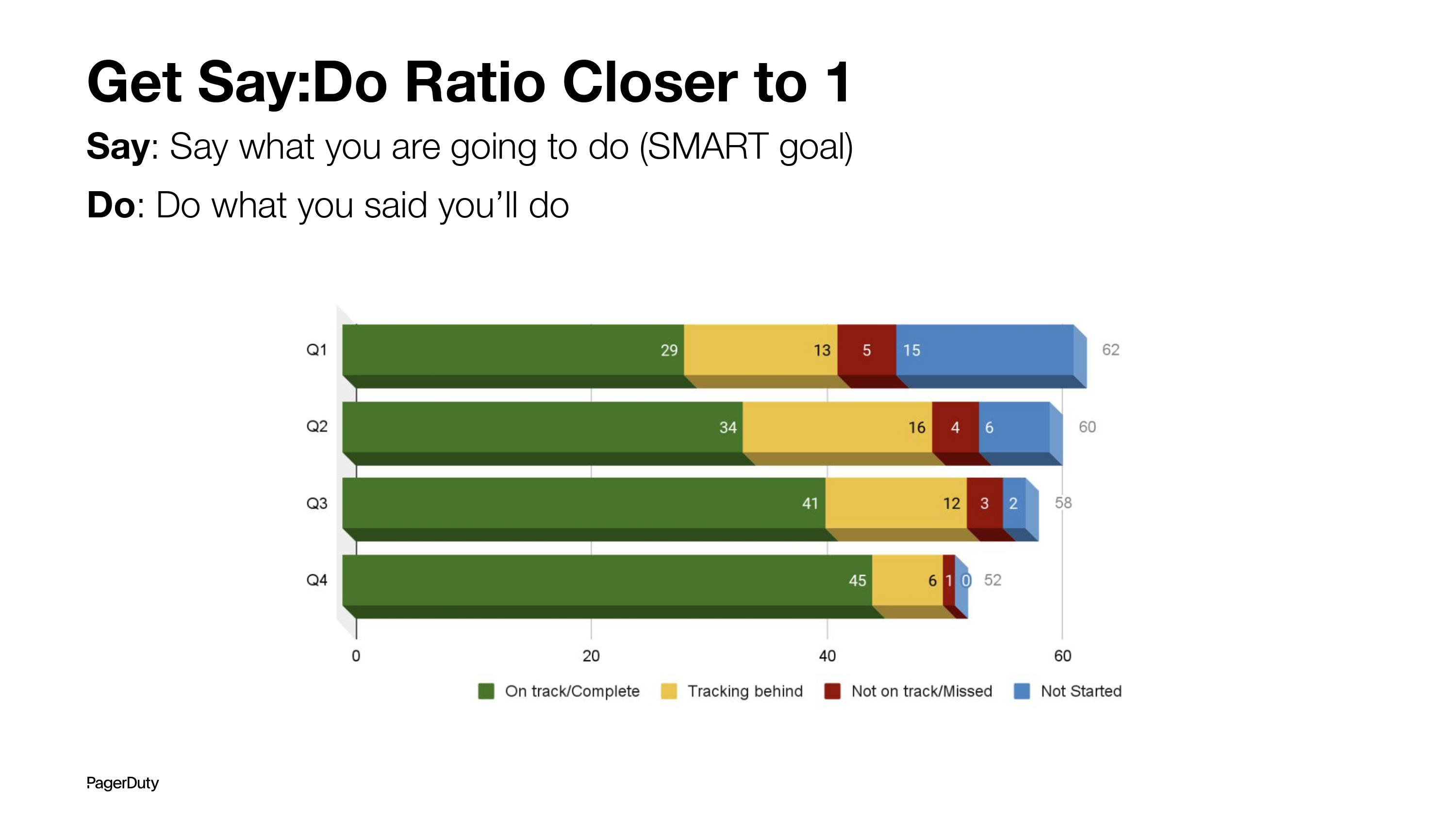
In the above graph, the X-axis represents the number of SMART initiatives — Specific, Measurable, Achievable, Relevant, and Time-bound goals we wanted to be true by the end of the year. They included reliability goals (such as SLA targets), people goals (such as engagement surveys and action items), and the majority were project goals (such as "Deliver X by Q3").
The total also represents the number of commitments in our annual plan (V2MOM). It’s designed to "fail from the bottom". We want it to be measured by 80+% to be done by the end of the year. For that, we break the SMART goals roughly into quarters and the 4 bars (Y-axis) represent progress in each quarter against the annual goal.
Shifting company culture
Once we’d defined the future, we needed a cultural transformation to get there. And I won’t lie — this can be delicate to navigate.
Our approach was to identify areas where we needed to evolve our culture, but still ground ourselves in the values and principles of the company. We brought accountability, focus on the customer, and focus on execution to the forefront of everything that we do.
We even updated our career ladder to make sure that execution and business impact appeared as required traits.

The slide above is an example of how we codified our culture shift. We brought some of these concepts to life, by applying them to ourselves and reinforcing them at every occasion, radiating this outwards, to the rest of the company.
To handle so many fundamental shifts, we had to bake them into our day-to-day work. That’s where we started having right-size processes that helped us stay aligned, and removed the cognitive overload for us to run together consistently. And that’s what we tackled in the next step.
3. Reset to execute
To bring this vision and cultural shift to life, we had to reset so we could execute. To accomplish this, we implemented a planning and execution framework at various altitudes.
Top-level: Long-Range Plan (LRP)
At the top level, we started with a long-range plan or LRP. This typically talks about the direction you want to head in three years from now and essentially paints a vision of where you want to be in three years. It doesn’t define any specific features—it just paints a picture of where you want to be as a team, as an organization, and as a product 3 years from now.
Yearly planning
Using LRP as a goal, we work backward to define the next year’s goal. In our case, it is reflected in our V2MOM.
It doesn’t matter which tool you use — it could be OKRs, the key here is to focus on prioritization. If everything is important, then nothing is. This whole structure of prioritization is designed to fail from the bottom, so you get the top priority items done and some of the nice-to-haves can potentially fall off.

Quarterly planning
Once the yearly plans are laid out, we get to the quarterly planning.
The goal for quarterly planning is to start on day 1 of every quarter with hands-on coding and development work — not planning work. To achieve this, the planning should start a couple of weeks earlier so the teams are aligned on what happens during the whole quarter.
Weekly planning
Once these things were in place, the final structure was the program core team, a cross-functional leadership group that meets weekly.
The idea for this meeting is to go through current items quickly. If any items require help, alignment, or course correction, this is the synchronous way for us to address them.
Defining and creating well-formed teams
We then shifted our focus toward creating well-formed teams. “Well-formed” is more static and structural — you can do that on paper, but getting healthy is a dynamic process.
We structured our teams to align with our business objectives, essentially looking forward from a 12–24 months perspective. We first started with team composition.

We started by defining that each team consists in around 7 people, with a healthy mix of seniority, skill sets, and other elements that are required for a team to function independently. We also looked at staffing ratios, so there’s enough coverage from a management and leadership perspective. It could be the engineering manager to developer ratio, EM to PM to design ratios, etc.
One of our mantras is that “All lists are prioritized, always.” We thus maintain a list of priorities for each team, and the backlog is designed to include more than what the team can do. “Above the line” are items we are confident we can deliver, and below the line are the uncommitted ones. Using this approach is really helpful to adjust.
So, the next thing was to streamline our team charters to make sure they were consistent. In some cases, we had to merge the teams, or something had to go below the line. Those are some of the hard decisions we had to make and work through. But in the end, we set up our teams to be autonomous for the charters they’re working towards.
We also considered operational load, because there’s tech debt, and that varies depending on the features. We also wanted to balance that with feature delivery and looking at other things, like planned vs. unplanned tasks, how many people would go on call, customer success metrics, etc.
The idea behind all of this is to make sure that the structure is visible and transparent to everybody and to a large extent to remove the mystery behind a lot of the decision-making that individual engineers might not be aware of.
Managing tech debt in partnership with product managers
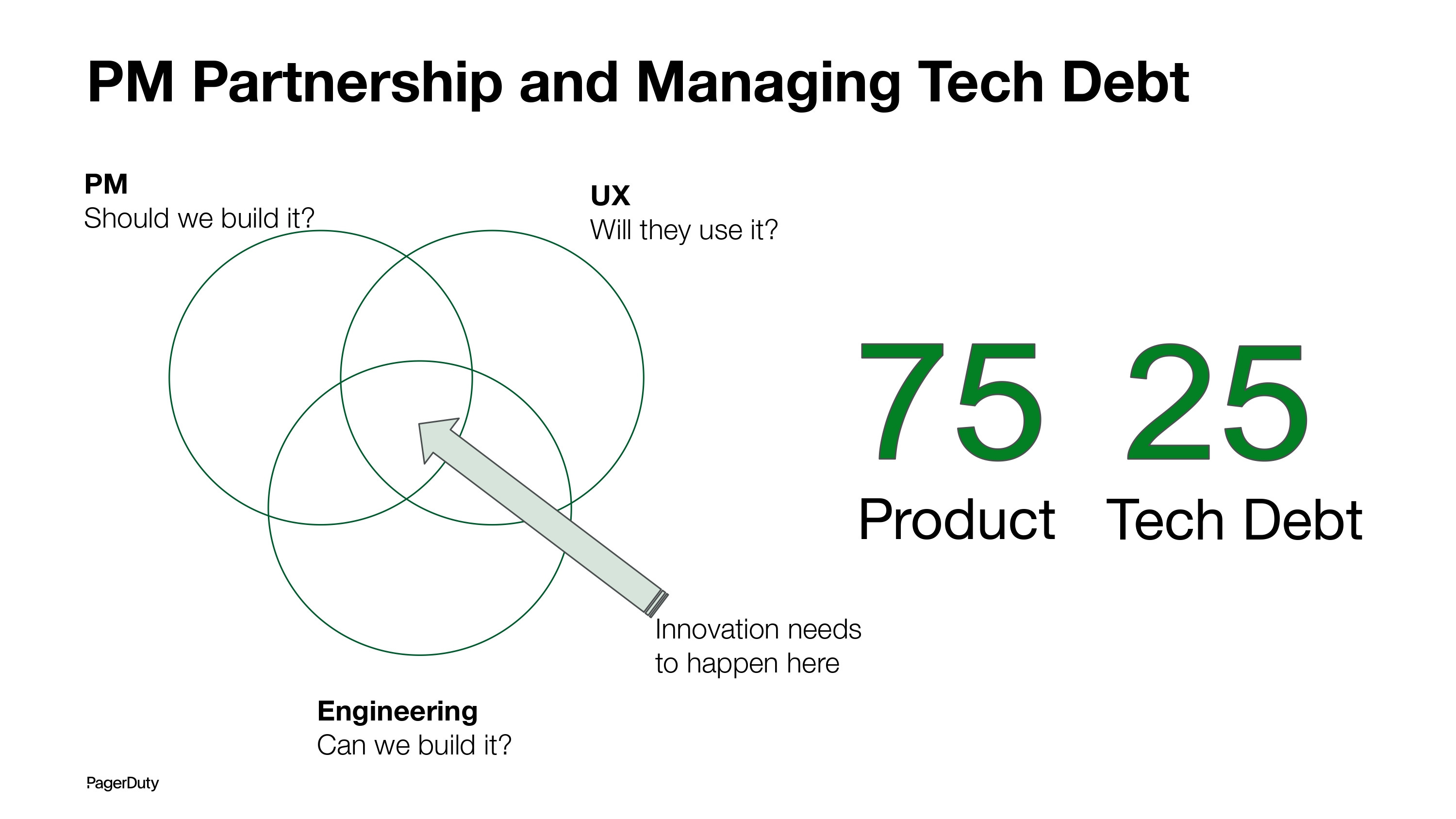
Finally, it’s worth mentioning the engineering and product partnership.
As leaders, we spend a lot of energy and time thinking about what’s next and how we get there. I believe that Engineering should not make plans in isolation (even for tech debt), and Product should not make commitments without engaging consistently with Engineering. A well-run org would behave like a 3-legged stool between Product, Engineering, and Design.
Engineering should not make plans in isolation, and Product should not make commitments without engaging consistently with Engineering.
With the EM and product partnership, we committed to tackling things together and not just tackling each other. We are in the same boat, so we have to look for ways to stay afloat.
One area where we’ve consistently worked on alignment is in deciding what goes in our backlogs and how items are added there. We used the discovery process and definition of ready* to help us make these decisions.
*Our definition of ready was as follows:
At least 5 customer validations
Product Brief / Lean Canvas ready
UX / Mockups ready
Risk assessment done (feasibility, viability, usability, etc.)
Technical design document written
From a feature development vs. technical debt perspective, we started with a structure where 75% of a team’s capacity would go towards product features, and 25% would go towards tech debt. We don’t always maintain this ratio every quarter, but it was a helpful benchmark to set.
Real-life examples at PagerDuty
If using Long-Range Planning (LRP), V2MOM, and Quarterly plans is a bit too abstract for you at this point, here are a few examples of how it worked for us at PagerDuty. These can vary from large programs like Internationalization, and New Service Region, to domain-specific projects like Analytics, to engineering-specific approaches like "API-first" policy.
For example, with API:
LRP: define a long-term API vision, from API standards, API-first approach where all features are first API accessible, API versioning, API backward and regression proofing, etc.
V2MOM: would now contain a subset of these visions, based on what exists today. For example, we did not have a standardized way of building and publishing APIs. Hence, last year, we took the project of defining API standards. From that point onwards, quarterly plans would have fractional goals based on that.
Another project-specific example was Analytics:
LRP: we defined how the Analytics stack needed to evolve
V2MOM: we defined the goal to bring the new tech stack, including moving customers over
Quarterly plans: we broke the goal into milestones, such as:
Bring the new stack in Q1;
Run the old and the new stacks in Q2 and Q3 in parallel for validation;
Q4: Start the End of life of the older stack and gradual rollout.
To conclude this part, if you’d like to bring your vision to life, you need to reset your organization and structure your teams and planning in the right way. Using Long-Range Plans (LRP), V2MOM (Vision, Value, Methods, Obstacles, and Measures), and Quarterly plans will help you break it down over the project duration!
Key learnings and next steps
To recap this guide, here are the three steps we went through at PagerDuty.
Step 1: we assessed the situation, using our experience and judgment to come up with a bespoke solution to the specific problem that we had.
Step 2: we defined the future state and what good looks like, so we could work backward from that. We also transformed our culture to focus on customer impact and execution.
Step 3: we reset our organization and teams, and structured them in a way that could make that execution possible. We created several frameworks and processes to ensure we would stay on track with as little overhead as possible.

The outcome of going through all these steps is that the same org has been doubling its output year over year, while consistently improving the quality and reliability of the product.
The whole process took 2 years from ideation to rolling it out across the company, and it came with its challenges.
For example, Change Management is a hard one — we first made the changes at the group level (Incident Management), and once it was proved to be a scalable process, it became standard across all of the product development. Our "Say:Do" ratio and V2MOM framework are now standard across the company! In the end, we are pleased with the results and better predictability we achieved over the years. Building on this framework, we are now focusing on making engineers more efficient and reducing the time to ship.
I hope this guide will help you improve the efficiency of your organization, and that, like PagerDuty, you’ll go from slipping to…shipping!
And that’s a wrap! Thanks to Manu for his invaluable insights, and see you next week for a new edition, or next month, for Elevate!
Cheers,
Quang & the team at Plato
Great article!