
#15 - How we turn data teams into better engineers at Netflix | Andrea Hairston, Manager, Data & Insights at Netflix
Netflix and skill


Hi there, hope you’re doing well! Time passes by, and we’re *already* celebrating the 15th edition of our in-depth article series, where we invite top-notch engineers from all over the world to share their wisdom with you. As usual, the assignment is the following: no-fluff, actionable, and precise insights from great leaders at great companies.
…and this is the same mission we have at Elevate, our annual conference for engineering leaders. This year, it’ll happen in San Francisco on June 5-6. Click that big button below to check the (incredible) line-up and get your ticket:
This week, we’ve invited Andrea Hairston, a mathematician turned data scientist, to share more about her daily life as an Engineering Manager, Data & Insights at Netflix, and to explain step-by-step, how you can turn data teams into better engineers. Let’s go!
Andrea Hairston, from Mathematics to Netflix

Andrea Hairston holds a PhD in Mathematics from Duke University, and started her career as a Research Mathematician in the US Department of Defense, working on Big Data. That’s where she found a passion for bringing technical people and domain experts together, to work on assignments in the most productive way possible. She spent close to seven years working for the government, before joining Booz Allen Hamilton as a Lead Technologist, sharing her data science expertise during consulting projects.
Close to 6 years ago, she joined Netflix as a Technical Program Manager, where her role was to support core data engineering across Netflix, making sure data analysts and scientists could make better decisions. Now a Manager for the Data Science & Engineering team, she still works toward the same goal, on a larger scale at the company.
When we think about a mathematician or a data scientist, we usually picture the cliché of a single person in their ivory tower, working on things that are too complicated for mere mortals to understand. Andrea is the complete opposite of this stereotype: she loves tough challenges, but she’s a great communicator and makes sure complex topics are consumable for everyone in the organization.
Besides Netflix, Andrea is a proud member of /dev/color, an organization that makes tech more diverse, day after day, and one of our dearest partners at Plato!
You can learn more about Andrea Hairston (and follow her) on LinkedIn.
How we Turn Data Teams into Better Engineers at Netflix
How can you turn data teams into better engineers? This is one of the more ambitious goals that I have set in my current role, so it’s something I’ve spent a lot of time thinking about and trying to address. In this article, I’d like to share a few case studies and key takeaways with you, but first, let me briefly introduce myself and my team.
I’m Andrea Hairston, Engineering Manager, Data & Insights at Netflix. I’ve been at Netflix for about five years in a variety of roles, almost all of them centering around alleviating pain points of some sort for internal customers.
I started my career as a mathematician working in big data for the U.S. Government. During my time there, I discovered and developed my skills for bringing domain expert analysts and highly technical researchers and developers together to solve tough problems. I saw an opportunity to leverage that skill by joining Netflix for a developer education role in the Data Platform organization.
Part of why I was initially hired into an engineering organization at Netflix was because of the data practitioner perspective that I could bring. Working in that role as a technical program manager exposed me to the back-end work data platform engineers were doing to support the needs of the rapidly growing business.
Meet my team: Data & Insights
First, a brief history of my team: During a company reorganization, data engineers moved out of the engineering organization to the Data & Insights organization to better support the needs for analytics and insights for the business. This reorganization created slightly more space between the platform infrastructure and the data engineers and analytics engineers who needed to leverage that infrastructure. A centralized engineering team within the Data & Insights organization was spun up to bridge that gap.
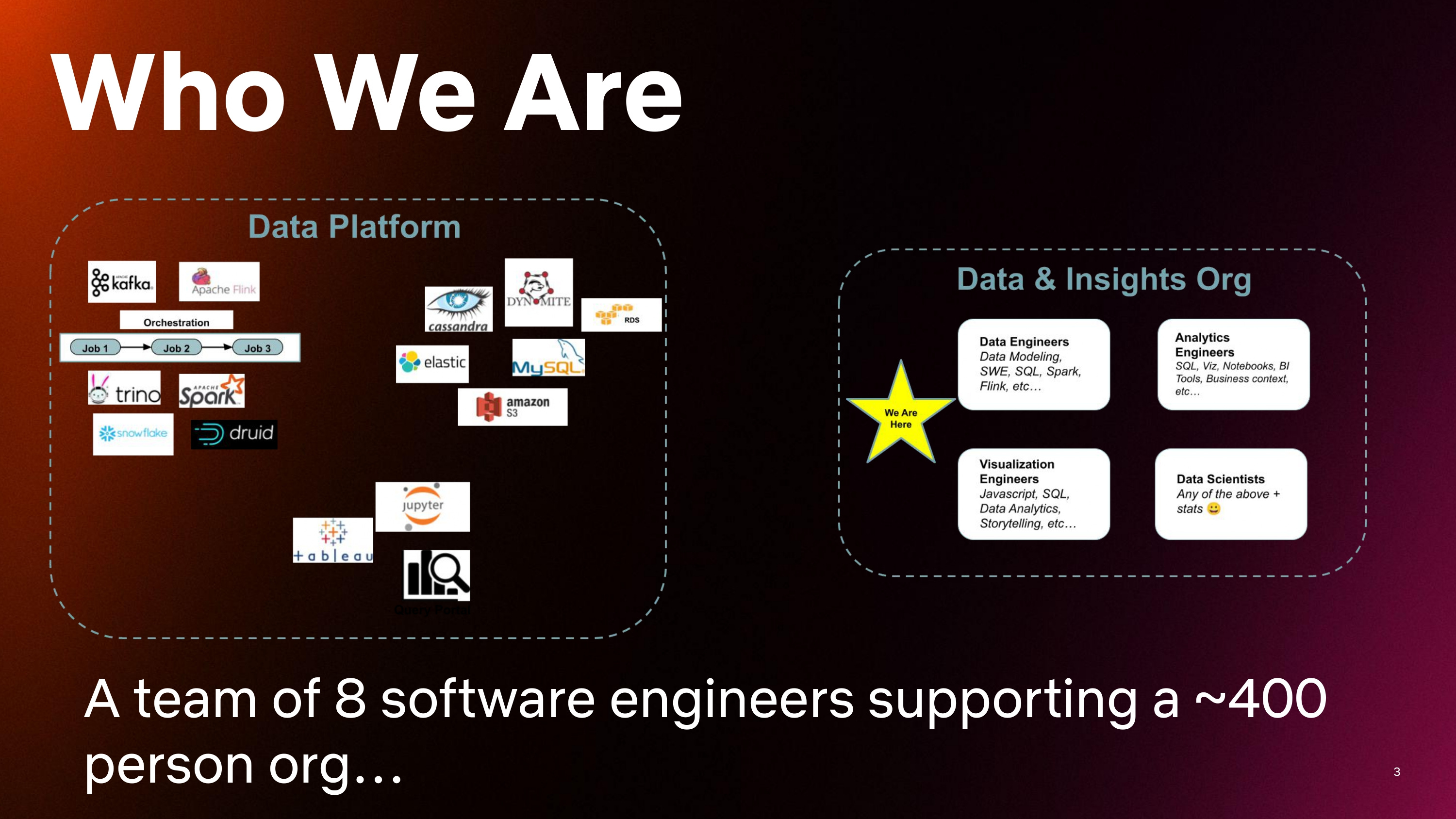
The slide above offers a simplified introduction to how data teams are organized at Netflix. On the left is our Data Platform team, which owns and maintains the data infrastructure that supports our data transformation, data transportation, cloud data storage, notebooks infrastructure, query portals, and business intelligence tools like Tableau.
And on the right, you see our Data & Insights org. One thing to note is it’s not just the Data & Insights org that uses the data platform. This data platform is powering data for our product and our studio, so many kinds of engineers are leveraging the platform.
Within the Data & Insights org, we have data engineers, analytics engineers, visualization engineers, and data scientists. Here’s a quick rundown of the skills required for each job family (though these are broad generalizations, of course):
Data engineers: data modeling, SW, SQL, Spark, Flink
Visualization engineers: JavaScript, SQL, data analytics, storytelling
Analytics engineers: SQL, viz, notebooks, BI tools, business context
Data scientists: any of the above + stats
I’m leaving out machine learning engineers and our scientists, but they have a dedicated machine learning platform.
My team is indicated by the yellow star on the slide. We’re not data scientists, we’re not fully data engineers, and not fully analytics engineers—we’re software engineers. It’s a small team of about 8, and we support this 400-person data and insights org. And we have one job—to enable them. I’ll share a bit more about how we do that throughout the rest of this article.
Our guiding principles
As the leader of this core team, I have three guiding principles:
Make it easy to do the right thing.
Don’t only ask teams what they want, take the time to understand what they do.
Meet teams where they are.
We value people over process.
These might sound like soft skills for an enablement team that’s trying to encourage people to use the infrastructure in the right way. But you have to remember this is Netflix: we value people over process. We avoid forcing people to do things here. We love our freedom and we embrace the responsibility that comes with it. Adhering to the above principles endear us to our customers while also getting us to our desired outcomes.
Let’s walk through some examples.
2 case studies: How we integrate our guiding principles into our work
Through two case studies, I’ll demonstrate how we abide by our guiding principles but also achieve the goal of making data practitioners better engineers.
You might be familiar with the quote from the movie Field of Dreams: “If you build it, they will come.” Well, I’m here to say it’s more complicated than that. Great engineering tools won’t make data teams better engineers. Remember that—I’ll come back to it. For now, let’s dive into the first example.
1. Workflow orchestration
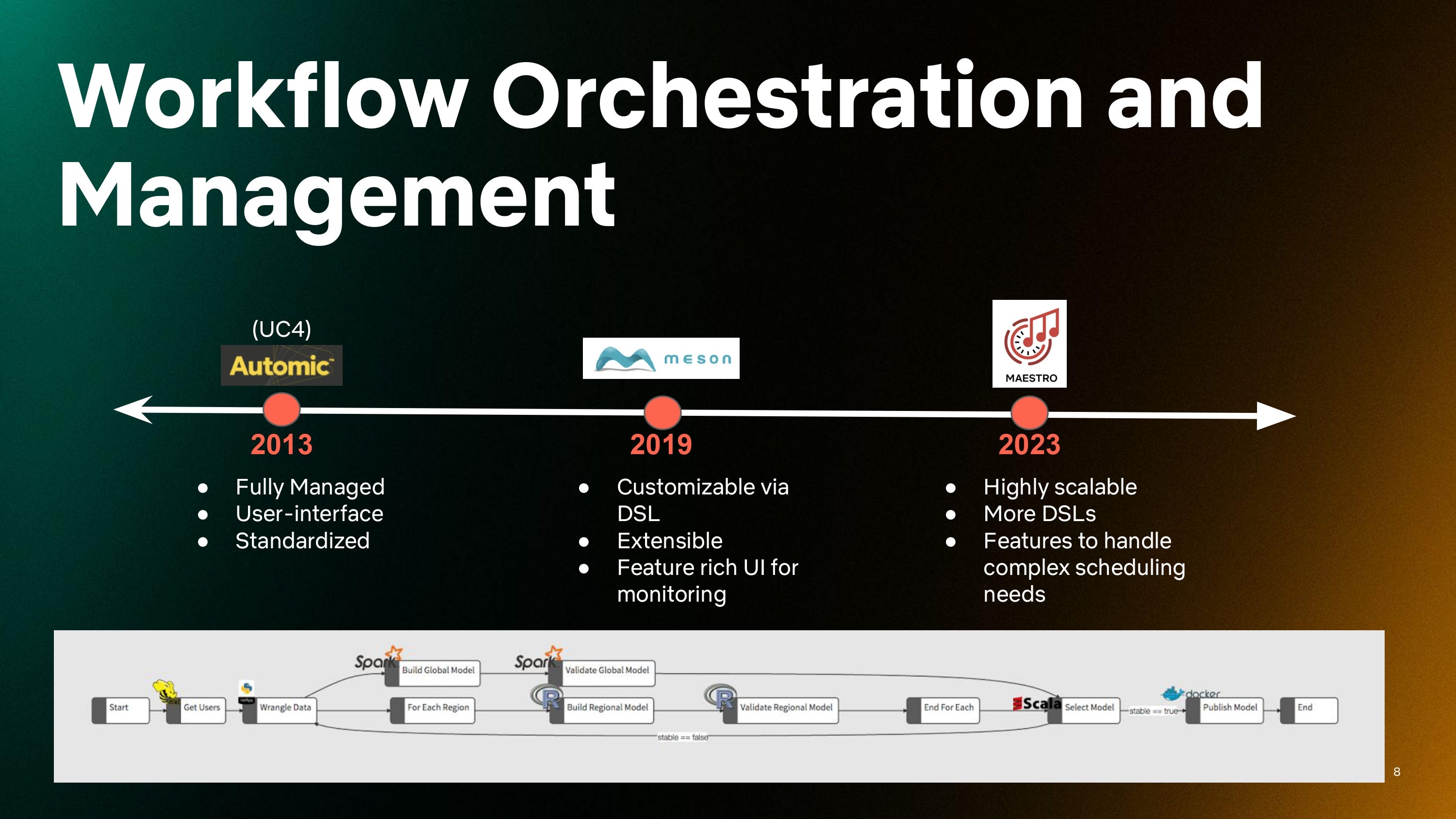
Ten years ago, we were using UC4, now known as Automic, to orchestrate data jobs. It was great back then—a very standardized application management system that was fully managed and had a very nice user interface that allowed users to set up jobs and run them with ease.
As Netflix evolved, we needed that tool to evolve. We built Meson, our next orchestration tool, from the ground up internally. It allowed us to do orchestration like what you see in the slide above, incorporating data from various parts of the data platform infrastructure, such as Hive and Spark Jobs, bringing them all together for deployment in Docker containers. It was very customizable, had a nice Scala DSL, fully extensible, and had a great UI for monitoring. This was an excellent engineering tool.
So why did it need to change? As data workflows became increasingly complex, especially on our machine learning teams, there was a need for more generic and flexible job orchestration, as well as Spark and Scala language support. Automic couldn't meet these requirements. Meson worked well for several years, but the number of workflows managed by the system had grown exponentially over the years. The next tool, Maestro, was developed to manage and schedule workflows at a massive scale while still maintaining SLO requirements.
Today we are using the second generation of Meson, which we call Maestro. It’s even more scalable to accommodate the size and scale of Netflix data as it’s grown and has even more DSLs, Java, Python, etc. It has better features for signaling and triggering jobs. It’s an excellent engineering tool.
It’s configurable, scalable, and reliable. But, its design assumes that users understand how to develop their own best practices around managing and deploying jobs robustly. Most data practitioners are not trained on best practices for collaborative code development. It is common at Netflix, for example, for teams to work out of one code repository with various source code files for data jobs that are maintained by separate individuals. Maestro makes it simple to run and orchestrate those jobs once they are defined but does not address code management.
[…] Flexibility allowed for quite a bit of disorganization within our data teams.
The software engineers in other parts of the engineering org and product org were able to leverage Maestro well. But it wasn’t helping our data teams go from data projects to robust data products. In fact, its flexibility allowed for quite a bit of disorganization within our data teams.
Our data practitioners started writing lots of code that lived in various places and deploying things from any convenient place. It became really hard for the data platform to debug pipelines when they failed. Data teams themselves were having a hard time collaborating and maintaining the jobs that they were writing.
Data practitioners even started getting nervous deploying things because they weren’t sure how it was going to affect downstream jobs. What will this change to this Python egg do to the rest of the pipeline when it’s deployed? It was a bit of a mess.
Maestro makes it simple to run and orchestrate jobs, but more was needed to help data teams with safer deployment strategies and implementing version control features that are common in software development. That's the need that we set out to fulfill.
So that’s where a team like mine steps in. In our minds, we’re saying: We have a great engineering tool. Our data teams are not leveraging it correctly. What are we going to do about that?
We started to think about the DevOps cycle. This is not a new concept, but data teams rarely utilize it. And to stay true to our corporate values, we didn’t want to force anyone to adopt it. So our question became: How do we build the tools that make it easy for them to do the right thing? (Just like our guiding principle.)
We wanted them to be able to deliver data products in a quick, safe, and repeatable manner, so we developed this tool called Dataflow.

I have to clarify that this is Netflix Dataflow—not to be confused with any other Dataflow product out there. I’m sure there are a ton of naming collisions, but it’s a great product.
This is an in-house tool. Currently implemented as a CLI—it provides automated code repo setup, automated CI/CD, unit tests, branch-driven deployment, and even sample workflow templates.
We released Dataflow in early 2023 and by the end of the year, we had 300 monthly active users, 50 daily active users, and over 300 Bitbucket repos across Netflix were managed by Dataflow configurations.
This was a prime example of how an engineering tool didn’t necessarily make the data engineers better, but we were able to bridge that gap by making it easier for them to do the right thing.

Above is an example of what a simple Dataflow command could do for you with a sample Spark SQL workflow. We give users a directory that gives you an SQL file, along with some unit tests that they can modify, but we handle the deployment configuration upon PR commit. Users don’t have to worry about any of that setup. Our goal is to have the users only be concerned with modifying the logic, in this example, modifying the SQL query to meet their needs. We even provide templates for backfill jobs—they don’t have to use any of them. But with the templates and scaffolding that we provide with this command, we nudge them to embrace all of it.
Dataflow is being widely adopted across our organization, and the platform loves it, too. The infrastructure team now has some simple config that they can point to when people need support debugging their jobs.
The Dataflow project will eventually graduate to the platform organization as a part of a larger productivity engineering effort. We are excited to see how that organization will evolve to be even more feature-rich and widely adopted.
2. Data analytics web app deployment
I mentioned earlier that great engineering tools won’t necessarily make data teams better engineers. And this second case study is another example.

In the analytics and visualization engineering space, we were hearing lots of pain points, like “I need an easier way to manage and deploy analytic web apps.”
The people I’m talking about live in the middle of the spectrum shown on the slide above. They’re a little more technically sophisticated than the Tableau and Superset users, who tend to prefer point-and-click dashboard development. However, they don’t have the JavaScript or the CSS skills to build their own React and Flask apps. They might work in R or Python, and they build R Shiny apps, Plotly dashboards, or Streamlit apps, but they want to deploy them to many stakeholders for interaction. These developers were feeling a lot of pain during that process.
If we just listened to what they wanted, we would have given them a great engineering tool. […] But when we dug deeper […] they were not using it at all.
We would have given them Spinnaker.

Spinnaker is probably one of the most successful open-source tools to come out of Netflix. It’s used at companies all across the country. It’s used ubiquitously at Netflix. The Spinnaker website describes it this way: “Spinnaker provides application management and deployment to help you release software changes with high velocity and confidence.” It’s a fantastic tool with a long feature list.
But when we dug deeper to see what the data professionals were doing, they were not using it at all. Instead, they were hosting web apps on their virtual machines and then sending the URLs to their stakeholders.

This was bad. We had no authentication for the users who were accessing the apps and thus the data. It was very risky. We had no reliability. The apps were being hosted on virtual machines that could go down at any time. And it was costly. At one point we counted 100 apps across VMs that were not in use.
Here’s a direct quote from a Netflix data scientist: “I’m open to learning the DevOps skills required to manage a Spinnaker app, but not currently having that skillset was a blocker for me to deploy the apps I was looking to spin up.”
This is where one of our guiding principles came in: We heard the pain, we saw what they were doing, so we met them where they were.
We could have said, “Alright, let’s spin up a curriculum to upskill people on Spinnaker, teach them how to open up the right ports in the firewall, and configure Nginx.” Sure, we could have done that. But do you want your data scientists doing that? Is that the best use of their time or the resources that you have?
For us, the answer was no. One of the engineers on my team spoke up, “There’s Posit Connect (formerly R Studio Connect) for this.” For the cost of $65k a year, we were able to host most of the types of apps that were being hosted on the virtual machines through Posit Connect.

Posit Connect is a platform for deploying web apps in Plotly, Streamlet, and R Shiny, and my team—the software engineers that understand how to do all that—maintains the platform instance on Spinnaker and we allow users to simply deploy through their R Studio IDE plugin or through a Python package in the environment that they love working in.
It was a huge win for us. The benefits far outweighed the costs.

Now we mitigate security risks, we route all the traffic through our internal application gateway, we save the data practitioners’ time, and we reduce costs. And if the web app goes down because the Posit Connect server goes down, that’s on us. I feel better about my team having to wake up in the middle of the night to address these server issues than the data scientist having to do the same.
Here’s a quote from the same data scientist from before: “With Posit Connect I found I’m able to focus my time on the analysis/dashboard design, without getting bogged down in the DevOps.”
And that’s what we want. We want them to focus on their expertise. But we also want all of the engineering best practices.
How does this team operate?
Now that you’ve seen a few examples of how we bring our guiding principles to life, I’d like to share a bit more about my team and how we operate.

Essential qualities of the team
I mentioned earlier that I have a small team: approximately 8 people supporting a 400-member organization. I manage very senior software engineers who have deep data experience. But more importantly, they’re also highly empathetic and patient. We’re highly collaborative. We sit with people to better understand what they’re trying to do. We work closely with the platform teams to understand their roadmaps and how our requirements may fit.
There is one other very important quality that contributes to the success of my team: We’re solutions-oriented. I know this sounds like a vague term that everyone uses on their resume, but what I mean is that we just aim to solve the problem. Posit Connect wasn’t an engineering project. We didn’t build anything, we didn’t design anything. We just said, “What’s the easiest and most effective way to address the problem?”, then we went and bought a license.
Ultimately, I manage these very skilled engineers who are humble enough to just want to solve problems and enable people. It’s an enablement-first team at the end of the day.
How I hire for and staff the team
I have to be very strategic about how I staff this team—both due to our small size and the balance of skills that are needed.
It can be difficult to hire for this team because of the broad context needed of how the Netflix platform infrastructure works, how data practitioners prefer to work, and the software development skills needed to build useful solutions.
Highly motivated internal candidates often desire to work for the team to be a part of the solution, but we have also had success with highly skilled external hires who tend to be very curious and motivated by the challenge of continuous context switching.
I hire software engineers with data in their background because user empathy is huge for our team's success, I also look for engineers with strong communication skills. Engineers that have worked on a variety of projects are also attractive, because our team has lots of flexibility on the types of solutions we choose to invest in that fit the enablement mission.
I often source opportunities from the team, so self-motivation and innovation are also crucial skills for any member of a team like ours.
How we measure success on the team

A natural follow-up question to what I have shared so far is, “How do you know that this team is doing a good job and that their efforts are valuable?” Mostly it’s feedback that we hear, but we do see a steady increase in the adoption of our tools.
We get positive feedback from new users, and I think that’s important—that new hires to Netflix come in doing the right thing because we’ve given them the tools to do so.
And then we see an improved quality and robustness of data products that can be traced back to our efforts.
We’re seeing effective collaborations with the platform—migrations have been able to be managed solely by the platform because there were code repos managed by Dataflow and they could hook into Dataflow and do what they needed to do. They could test. They could observe. And it’s just been a win all the way around.
Key learnings and what’s next
At this point, you might be thinking—that’s Netflix, you have a 400-person data org, but that’s not where I work. But keep in mind, we’ve only allocated about 2% of our headcount in the data org to enabling our data practitioners.
You cannot be a successful enablement team without empathy — Andrea Hairston
If you take anything away from this article, please understand the investment in a team like this is worth it. Two percent for you might be one person, but I think that’s worth it to allow data product developers to focus on their area of expertise and not get bogged down in DevOps.
Here are my other key learnings:
Don’t force data product developers to be software engineers. Invest in tooling or people that can help get data practitioners on the unique data development paved path.
You cannot be a successful enablement team without empathy. Understanding what your users are trying to do, and why, helps to inform the right solution. If all we wanted to do was point people to documentation for great engineering tools, we would not be successful. We have to have real empathy for what the data teams are trying to do to find the right solutions for them.
“Bake in” best practices whenever possible. Reducing the friction associated with following best practices is the best approach when mandates are not an option. We could say, “It’s a best practice to write unit tests for your data pipelines,” but for certain use cases, there can be a lot of friction in doing that without a valuable return, so we tried to bake it into Dataflow so that users had the smallest, easiest lift to make it happen. We bake in data audits as well. We just ask them to insert the logic. Again, my advice is to reduce the friction as much as possible if you want people to follow best practices, especially when mandates are not an option. I think a lot of startups operate like that as well, so that might be relevant to you.
Looking to the future, what’s next for our core team? We’ve invested heavily in enabling data engineers in our organization. As a sign of success, many of those solutions are now graduating to the platform engineering teams to maintain and develop further.
The analytic engineer is another role in the Data & Insights org that could benefit from tooling to help them better leverage the platform tools available. They have needs unique to their skill sets, workflow patterns, and work products, and my team is eager to grow into developing more solutions for those personas.
As we lean more into analytics, our solutions may start to look less like extensions or abstractions on the existing platform infrastructure and more like a small platform itself. This will require more resources for the team and a new scope of responsibility. It’s an exciting challenge that we are embracing.
I hope the case studies and takeaways I’ve shared here have inspired you to think about how you can bridge the gap between data teams and engineers in your organization.
We hope you enjoyed this guide as much as we did! If so, there’s a small thing you can do for Andrea:
Cheers,
Quang and the team at Plato